Mettre en place une couche sémantique dans une modern data stack n’est plus un luxe, mais le moyen le plus fiable de rendre la donnée vraiment accessible, actionnable et alignée à l’échelle, surtout quand l’IA entre dans l’équation. Cet article propose un retour sur la Forward Data Conference et sur l’évolution de la couche sémantique augmentée par l’IA depuis novembre 2025, à travers le prisme de Microsoft Fabric, Foundry et Copilot.

Vue d’ensemble
- 01 Qu’est-ce qu’une couche sémantique
- 02 De la donnée à la décision : rendre l’analytique vraiment actionnable
- 03 Alignement, gouvernance et IA : une IA qui ne “devine” plus
- 04 Microsoft IQ : une IA agentique multi couche
- 05 Cas d’usage : gestion des impayés fournisseurs avec Fabric et Copilot
- 06 FinOps de l’IA agentique : Pay as you go vs PTU
- 07 Comment démarrer : trajectoire recommandée et perspectives
Qu’est‑ce qu’une couche sémantique ?
La couche sémantique, au‑delà des outils, est cette représentation structurée des concepts métiers (clients, revenus, abonnements, canaux, etc.), de leurs relations et de leurs règles de calcul, partagée entre métiers, data et désormais agents IA. Dans une modern data stack sans langage commun, chaque équipe recrée ses définitions – “ARR”, “active subscription”, “NPS”, “channel performant” – ce qui force tout le monde à faire de la traduction permanente et génère du gaspillage de temps.
Même avec une stack très outillée (ETL/ELT, data warehouse type Snowflake, orchestrateur type dbt, reverse ETL, BI, voire Azure AI Foundry), rien ne garantit que tout le monde consomme la donnée de la même façon. La couche sémantique agit comme single source of truth, exposant un lexique commun, une vérité partagée et une documentation structurée, pour éviter les écarts d’interprétation – autant pour les équipes que pour les LLMs.
Dans ce contexte, son premier bénéfice visible est de rendre l’accès à la donnée « low effort » et donc réellement no code pour les décideurs, via des assistants IA de type chat BI qui cachent la complexité du data warehouse derrière le langage naturel. Ces assistants peuvent être consommés directement dans des outils de travail quotidiens comme Microsoft Teams, notamment via des mécanismes de type MCP (Model Context Protocol) ou des intégrations agents/Teams déjà démontrées avec Snowflake.
De la donnée à la décision : rendre l’analytique vraiment actionnable
Une couche sémantique ne sert pas uniquement à standardiser des métriques, elle sert à produire des analyses réutilisables et orientées usage, avec des résumés, explications et recommandations directement exploitables. C’est ce qui permet de passer de dashboards statiques à des réponses contextualisées, alignées sur un contexte métier (segment, période, territoire, canal) sans recréer un rapport à chaque question.
Un point clé est la séparation des rôles :
- L’équipe data centralise, transforme, fiabilise et structure des “topics” ou modèles sémantiques.
- Les équipes métiers s’approprient le “dernier kilomètre” via le prompt, les filtres métier et la configuration d’alertes ou de résumés dans Teams, Power BI ou Copilot.
Concrètement, cela réduit drastiquement le temps passé à décliner des variantes de rapports (“7 jours vs 30 jours”, “France vs EMEA”) puisque la base sémantique est déjà prête et que les agents se chargent de l’adaptation contextuelle. Le rôle de la BI évolue : elle ne se limite plus à exposer des tables fiables, elle fournit la grammaire métier que les agents IA utilisent pour produire des recommandations plus directement actionnables.
Alignement, gouvernance et IA : une IA qui ne “devine” plus
Dès qu’on introduit des LLMs dans la consommation de données (text‑to‑metrics, chat BI, copilotes), l’ambiguïté devient un risque opérationnel : si la définition d’un indicateur est floue, le modèle peut “inventer” une interprétation erronée. La couche sémantique devient alors un actif de gouvernance : consommée par les LLMs eux‑mêmes, elle doit être précise, propre, bien documentée et non ambiguë pour limiter les hallucinations et les erreurs de calcul.
Lors de la conférence de novembre, l’exemple de Photoroom montre comment pousser cette logique dans dbt avec une approche “DRY” : une définition centrale, pas de doublons, une exigence élevée de documentation et de tests autour de la couche sémantique. Des plateformes cloud‑native comme Sigma ou Omni s’inscrivent dans cette même tendance : connexion directe au data warehouse, requêtage live, self‑service gouverné et semantic layer partagé, avec IA intégrée pour assister l’analyse.
En parallèle, Microsoft fait évoluer son approche en transformant le semantic model Power BI en socle d’un modèle sémantique étendu (ontologie, graphe, agents), sous la bannière Fabric IQ. L’enjeu n’est plus seulement la cohérence des chiffres affichés, mais la capacité à aligner l’IA, la BI et les processus opérationnels sur un même langage métier, partagé et gouverné.

Microsoft IQ : une IA agentique multi‑couche
Avec le programme Frontier, Microsoft formalise son « intelligence layer » autour de trois composantes : Foundry IQ, Fabric IQ et Work IQ, qui s’imbriquent pour faire travailler des agents IA sur une sémantique unifiée. Dans ce cadre, le modèle sémantique devient multi‑couche : une plateforme centrale permet de concevoir, déployer et orchestrer des agents IA qui s’appuient sur les mêmes définitions métier, quel que soit l’outil utilisé par les équipes.
Microsoft Foundry / Foundry IQ – couche de conception et de déploiement
Foundry est une plateforme PaaS pour concevoir, tester et déployer des applications et agents IA, avec Foundry IQ comme couche de connaissance gérée qui transforme les données d’entreprise en bases de connaissances réutilisables, permission‑aware. Ces agents sont ensuite consommables par Microsoft Fabric, Copilot et plus largement l’écosystème Azure.
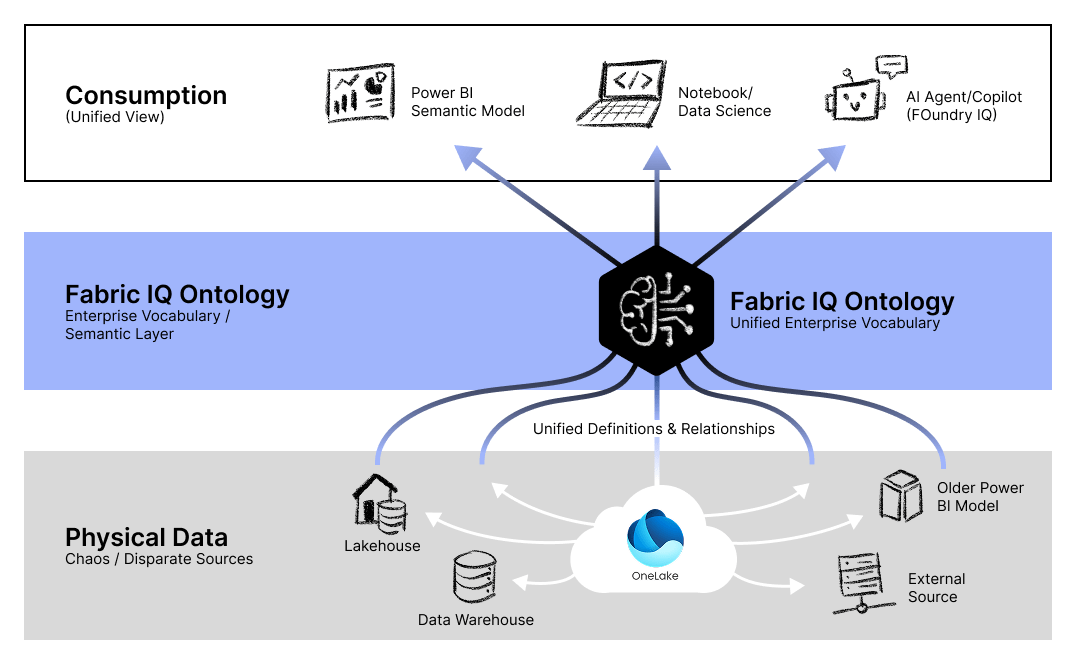
Microsoft Fabric / Fabric IQ – couche de données et d’intelligence sémantique
Fabric IQ est un nouveau workload qui unifie les données dans OneLake et les organise selon le langage de l’entreprise, via une ontologie métier, un moteur de graphe et un semantic model étendu. Il transforme Microsoft Fabric d’une simple plateforme de données en une plateforme d’intelligence où données, sens et actions convergent pour alimenter agents et utilisateurs métiers.
Microsoft Copilot / Work IQ – couche d’assistance et d’usage métier
Work IQ capte la façon dont les utilisateurs travaillent dans Microsoft 365 (documents, réunions, conversations, workflows) pour fournir une assistance contextuelle, notamment via Copilot dans Teams, Outlook, Word, Excel ou Power Platform. Copilot exploite ainsi les données et modèles préparés dans Fabric IQ et Foundry IQ pour proposer des réponses, résumés ou actions alignés sur le contexte de travail réel.
Dans Fabric IQ, la signification métier n’est plus enfermée dans la BI : elle devient réutilisable dans les tableaux de bord, les requêtes graph, les analyses transverses et les agents opérationnels qui se branchent directement sur l’ontologie. Cette approche limite les logiques dupliquées, crée une couche décisionnelle partagée et facilite l’automatisation de cas d’usage IA plus complexes.
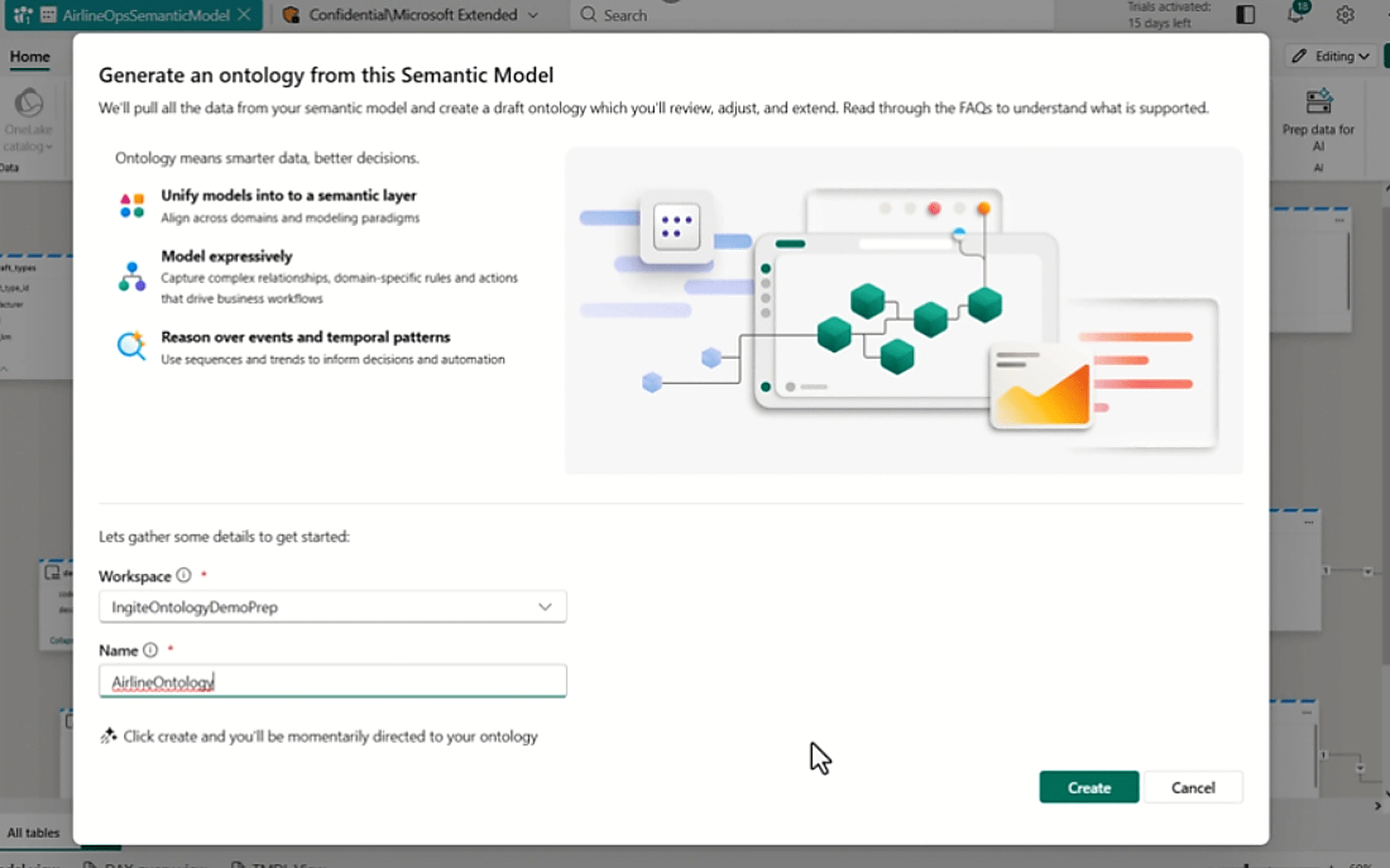
Cas d’usage : gestion des impayés fournisseurs avec Fabric et Copilot
Pour illustrer l’articulation des trois couches d’intelligence dans un cas d’usage à fort impact, prenons un agent dédié au suivi des impayés fournisseurs.
- Fabric pose la grammaire métier : “facture échue”, “fournisseur stratégique”, “blocage logistique”, “litige ouvert”, “relance niveau 1 ou 2” et les règles qui relient ces concepts.
- AI Foundry/Foundry IQ récupère les éléments utiles depuis l’ERP, les contrats, les pièces jointes, SharePoint et OneLake, en préservant autorisations et contexte documentaire.
- Copilot, via Teams/M365, ajoute le contexte opérationnel réel : échanges Teams, réunions achats, workflows de validation, commentaires sur les dossiers.
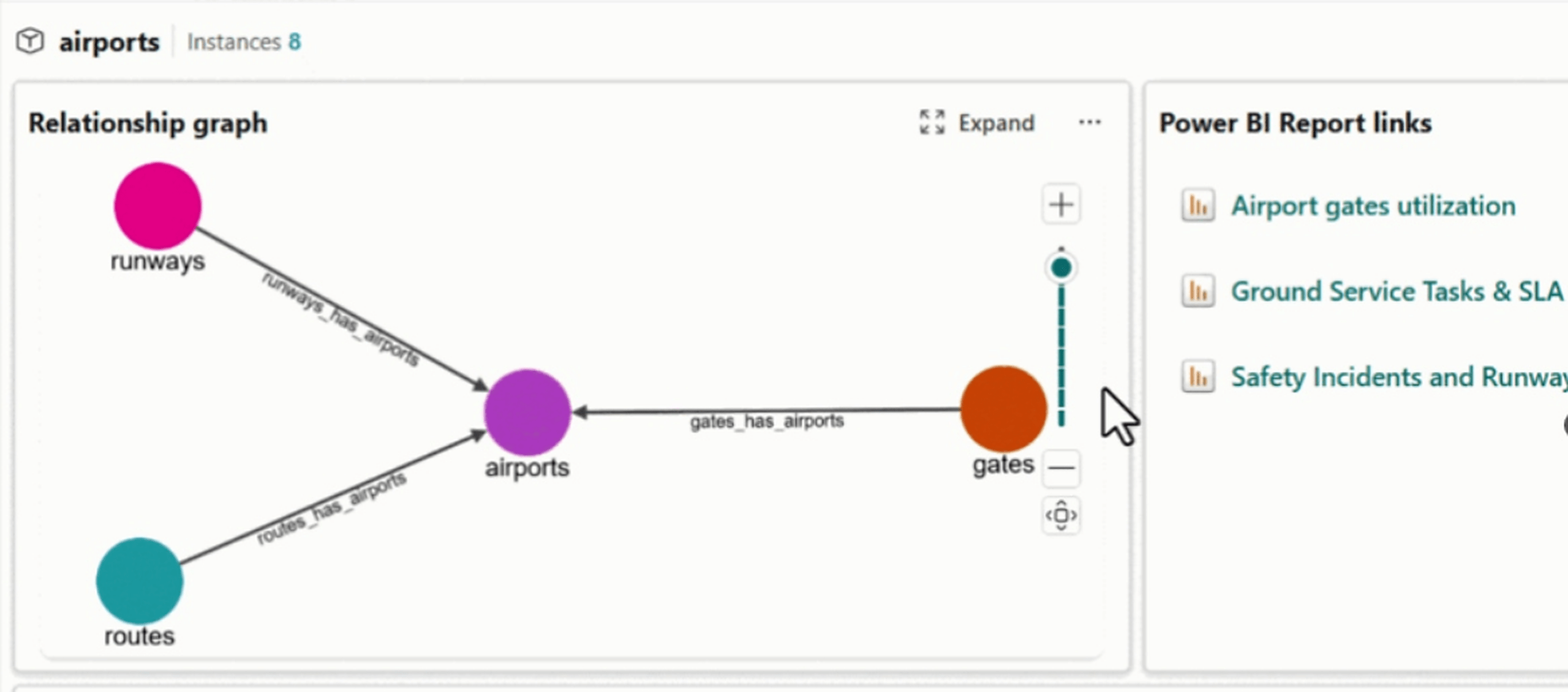
Quatre indicateurs clés émergent après mise en place d’un tel agent :
+30%
Productivité des équipes finance/achats : gain estimé sur le traitement des dossiers de recouvrement selon plusieurs benchmarks IA.
-20%
Réduction des impayés à risque : Obtenu par des solutions IA spécialisées dans des contextes moins industrialisés qu’une architecture multi-couches.
-60%
Économies financières : Réduction des agios après un an d’utilisation de son module de recouvrement.
<30%
Taux d’automatisation utile : les benchmarks recommandent de viser un taux d’escalade humain inférieur à 30%, en mesurant les cas traités de bout en bout par l’agent.
La rupture est que le système n’attend plus qu’un utilisateur pose la bonne question ; grâce à l’ontologie et au graphe, il peut parcourir les relations entre événements, objets, équipes et processus pour détecter plus tôt les combinaisons à risque ou les opportunités d’action. L’agent ne voit plus seulement une facture échue, il relie ce signal à un litige qualité, à un fournisseur stratégique, à un retard logistique ou à une contrainte contractuelle pour identifier un risque plus large sur les approvisionnements et la continuité opérationnelle.
FinOps de l’IA agentique : Pay‑as‑you‑go vs PTU
Sur le plan FinOps, il est utile de distinguer deux types de consommation : l’IA générative “classique” et l’IA agentique orchestrée via Foundry et Fabric.
- Pour l’IA générative, la consommation se mesure en tokens par minute (TPM) et requêtes par minute (RPM), ce qui permet d’estimer les coûts et de dimensionner la scalabilité avec le gestionnaire de compte.
- Pour l’IA agentique, deux modes de déploiement se distinguent : Pay‑as‑you‑go et Provisioned Throughput Units (PTU).
Le modèle Pay‑as‑you‑go facture à la consommation réelle, au token, sans engagement préalable, ce qui le rend adapté aux POC/MVP ou aux workloads au volume encore incertain. Il permet une expérimentation contrôlée, proche d’une logique de consommation BI Azure, avec la possibilité d’options globales pour maximiser le débit sur l’infrastructure mondiale.
Les PTU correspondent à une capacité réservée, garantissant latence et priorisation de traitement, recommandée pour les agents en production avec volumes de requêtes stabilisés et SLA exigeants. FinOps‑wise, cela transforme une dépense variable en coût fixe maîtrisé, préférable lorsque le ROI du cas d’usage est démontré et que l’agent est sollicité par des dizaines ou centaines d’utilisateurs.
La trajectoire recommandée consiste donc à démarrer en Pay‑as‑you‑go pour qualifier le cas d’usage, mesurer les volumes et estimer le coût à l’échelle, puis basculer en PTU une fois la production stabilisée. Cette approche en deux temps – validation puis industrialisation – s’inscrit naturellement dans une démarche FinOps rigoureuse en limitant le risque de sur‑engagement capacitaire.
Comment démarrer : trajectoire recommandée et perspectives
L’offre Microsoft se distingue par une approche intégrée de bout en bout, qui prolonge les modèles sémantiques Power BI et OneLake vers une ontologie métier graphée, consommée à la fois par Fabric IQ, Foundry IQ et Copilot/Work IQ. Avec cette base, il devient possible d’industrialiser des agents IA fiables, de rapprocher métiers et IT et de transformer la donnée en actif opérationnel réellement actionnable.
Une bonne approche de départ consiste à couvrir 2 des 3 couches intelligentes en ciblant un cas d’usage précis (par exemple un agent de recouvrement ou de FP&A) : création d’un agent dans AI Foundry, connexion à un modèle sémantique Fabric existant, exposition dans Copilot/Teams. Le pattern “un agent = un cas d’usage” reste le plus efficace pour itérer rapidement, comme cela a été discuté dans les échanges post‑Fabcon 2026.
Grâce à la notion d’ontologie, ces approches réconcilient BI “classique” (analyse du passé et du présent) et analyse prédictive tournée vers le futur, pour des cas comme FP&A, EPM ou SPM. Elles rendent ces scénarios multidimensionnels plus accessibles, mieux intégrés à l’écosystème Microsoft et potentiellement moins coûteux que des modèles de machine learning spécialisés, autrefois cantonnés à des outils hors Fabric.