
Matillion Avancée
Passez à la vitesse supérieure avec Matillion : cette formation vous permet d’aller plus loin dans l’intégration de données cloud avec des traitements avancés, des API et la gestion de versions.

Article rédigé par Eric Moss – Consultant BI ActinVision
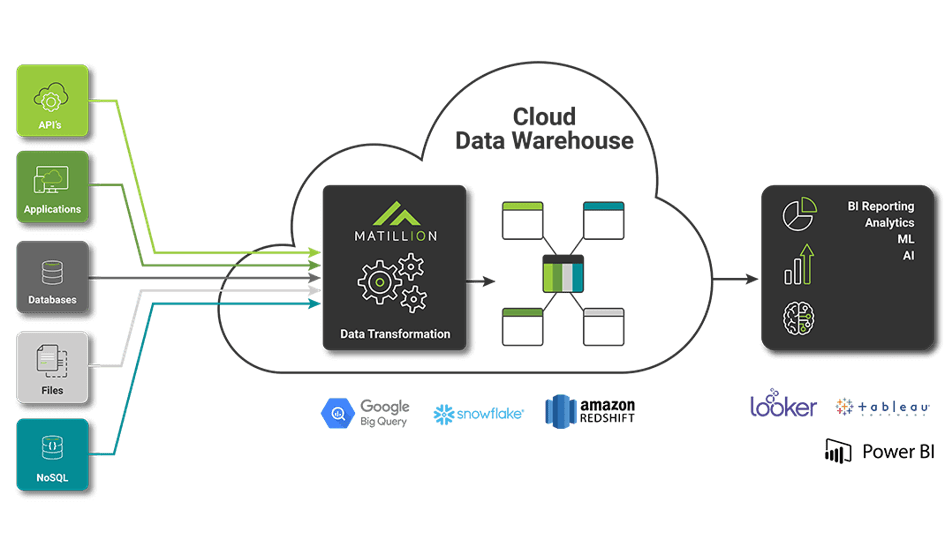
La société Matillion a créé un outil de traitement de la donnée qui extrait les données, les charge dans une base de données puis les transforme. Contrairement à d’autres outils avec des utilisations similaires tels que Talend, Informatica PowerCenter ou Oracle Data Integrator, Matillion est 100% Cloud. Il n’y a donc aucun besoin d’installer un serveur. Il suffit simplement de louer une machine virtuelle via Amazon Web Services, Google Cloud Platform ou bien Microsoft Azure.
Dans cet article
Cet outil est dit ELT : Extract, Load and Transform. Contrairement à d’autres outils avec des utilisations similaires tels que Talend, Informatica PowerCenter ou Oracle Data Integrator, Matillion est 100% Cloud. Il n’y a donc aucun besoin d’installer un serveur. Il suffit simplement de louer une machine virtuelle via Amazon Web Services, Google Cloud Platform ou bien Microsoft Azure.
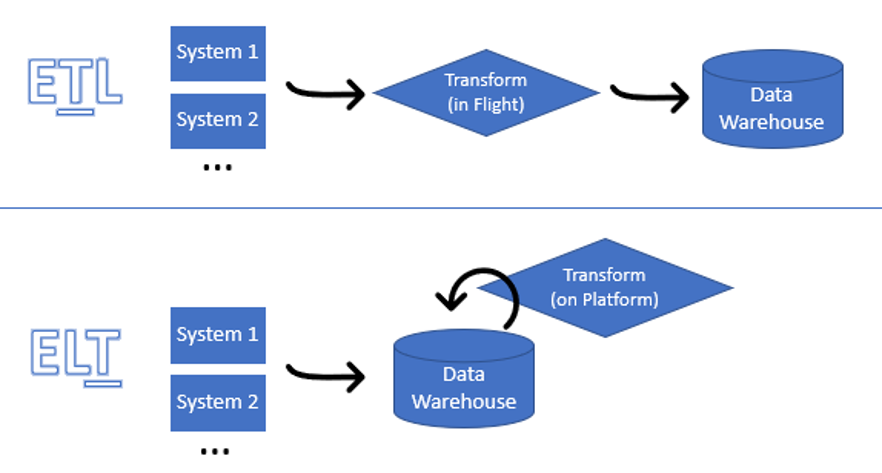
Pour comprendre comment fonctionne Matillion, il faut d’abord comprendre la différence entre un ELT et un ETL (Extract, Transform and Load).
Dans les deux approches, la première phase commune est l’extraction des données provenant d’une ou plusieurs sources. Les sources peuvent être diverses comme des fichiers plats, une API, une base de données, un ERP, etc. La différence entre ETL et ELT réside dans la seconde étape : contrairement à un ETL, un ELT charge directement les données dans l’entrepôt de données (Data Warehouse, DWH). Il insère les données de façon brute dans une partie de l’entrepôt qualifiée de base de Staging. Ainsi, les données sont dès la première étape dans la base de données cible qui servira à leur exploitation. Dans le cas d’un ETL, il faut généralement installer un serveur sur lequel est localisé l’outil de traitement des données. Dans ce cas, la donnée est d’abord chargée puis transformée et enfin insérée dans le Data Warehouse. Avec un ELT, la donnée est chargée une seule fois, puis elle est transformée.
Pour les transformations, un ETL utilise les ressources du serveur où il se situe ; il a donc besoin de sa propre puissance de calcul, indépendamment de celle allouée à la base de données – les traitements sont « externalisés ». De son côté, L’ELT utilise directement la puissance de calcul de la base de données puisque les traitements sont réalisés in situ, au sein même de la base de données cible. Les traitements sont écrits dans le langage propriétaire de la base de données (SQL) car la donnée ne quitte jamais la base. L’ELT utilise la base de données cible tel un outil pour réaliser les manipulations requises. Il mutualise les ressources de calculs pour les traitements, les expositions et le stockage.
L’utilisation de l’outil de traitement des données Matillion est simple. Depuis l’interface, on choisit des composants à déposer sur l’espace de travail. Ensuite, il suffit d’ordonner son besoin. Avec les différents composants de l’outil, il est ainsi possible de :
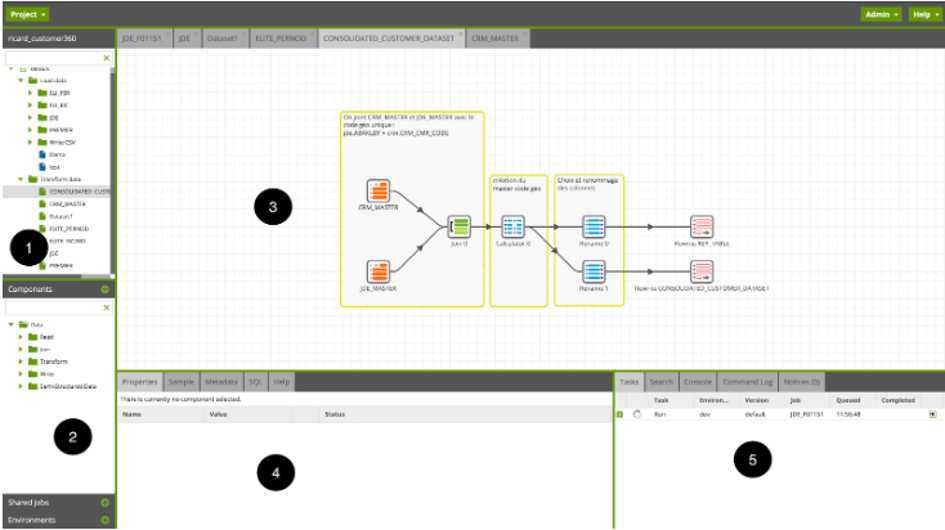
L’interface est composée de 5 parties :
1- L’arborescence des Jobs créés ;
2- La liste des composants disponibles ;
3- L’espace de travail du Job ouvert ;
4- La zone des caractéristiques du composant sélectionné ;
5- Et enfin la liste d’exécution des tâches et des Logs.
Matillion propose ce que font plusieurs autres outils du marché (Informatica PowerCenter, Talend…) mais en ELT. Toutes les actions disponibles dans l’interface sont traduites en code SQL et sont transmises au Data Warehouse chargé d’exécuter ce même code. Matillion ne fait que générer le code SQL ; de ce fait, il ne peut pas fonctionner sans entrepôt de données. Matillion est l’orchestrateur des traitements et des transformations.
Ce qui différencie Matillion est qu’il est 100% Cloud et qu’il s’appuie exclusivement sur des solutions d’entrepôts de données dans le nuage informatique. Matillion facilite la connexion à ces entrepôts de données et permet de profiter de leurs avantages : puissance de calcul disponible à moindre coût, tarification sur mesure, couplage avec d’autres services également managés dans le Cloud.
Matillion se décline en trois solutions, toutes connectées à un service de Data Warehouse Cloud. Nous retrouvons ainsi :

Ces solutions mettent à disposition différentes fonctionnalités propres aux services d’entrepôts de données concernés. Cela permet à l’utilisateur de pouvoir choisir sa version de Matillion en fonction de son hébergeur Cloud et de ses préférences ; chacun des entrepôts de données ayant ses avantages et ses inconvénients. En guise d’exemple, Snowflake gère l’auto-extinction des machines après un temps d’inactivité choisi par l’utilisateur depuis l’interface, ce qui permet une économie d’argent considérable contrairement à Redshift qui, pour le moment, ne le permet pas.
En outre, les trois solutions de Matillion possèdent exactement la même interface ; les composants d’orchestration et de traitement sont également les mêmes. Ils peuvent cependant se différencier par les fonctionnalités que chacun des trois entrepôts Cloud propose.
Les avantages de Matillion :
Matillion possède 2 catégories de Jobs : les Jobs d’orchestration et ceux de transformation. Les Jobs d’orchestration s’utilisent pour la récupération des différentes données à partir d’une ou plusieurs sources extérieures au Data Warehouse, pour la modification du modèle de données ainsi que pour le chargement & l’orchestration des différents traitements. Les Jobs de transformation sont quand à eux concernés par la lecture des données récupérées, par les différentes jointures, par les calculs à réaliser et par l’écriture.
Comme pour Talend, un Job d’orchestration peut appeler d’autres Jobs, d’orchestration ou de transformation. Ce qui fait qu’un traitement peut être réutilisable plusieurs fois, avec ou sans condition. Les composants utilisés par les Jobs sont différents suivant le type de Job utilisé. En ce sens, un composant utilisé dans un Job d’orchestration a peu de chance d’être aussi disponible au sein d’un Job de transformation, et inversement.
Matillion possède un très grand nombre de composants différents. La difficulté majeure réside dans le fait de trouver le composant pouvant précisément répondre à votre besoin ; car il peut être facile de s’y perdre ou de mettre un certain temps avant de savoir exactement quel composant mettre en place. Par exemple, si nous avons besoin de récupérer des données depuis un ERP, il est nécessaire de fouiller parmi les différents dossiers contenant les composants pour essayer de savoir lequel est propice. En outre, puisque la solution est relativement récente, il y a pour l’instant peu d’utilisateurs au sein de la communauté pour trouver de l’aide.
De part les éléments qui suivent, Matillion ressemble à d’autres outils de traitement de la donnée (Talend, PowerCenter…) :
Drag & Drop des différents composants pour la construction des flux ;
Disponibilité de nombreuses fonctions natives ;
Facilité d’orchestrer les différents traitements.
Une personne connaissant un ou plusieurs outils similaires pourra rapidement prendre en main Matillion. Ce dernier est finalement très visuel et il est facile d’avoir une idée du flux de données mis en place. Il est également aisé de savoir quelles sont les données chargées et où elles sont traitées, quelles sont les manipulations réalisées et tout ceci étape par étape. C’est pour cette raison que je pense que les novices aux outils de traitement de données peuvent rapidement comprendre la logique qui se cache derrière Matillion.
Un des plus de l’outil est également qu’il y a un « Check » de validation pour chaque modification réalisée. La possibilité d’avoir un échantillonnage des données traitées existe également : cela permet de rapidement valider son travail, de vérifier si les traitements répondent au besoin et de corriger les erreurs le cas échéant.
Matillion fait tout son possible pour pouvoir se connecter aux différentes sources de données existantes. La gamme de composants disponibles permet de répondre efficacement à cette problématique. La seule ressource qui n’est pas accessible pour Matillion est celle qui se trouve en local ; il faudra forcement que l’outil puisse se connecter en ligne à la source pour pouvoir récupérer les données. Il convient néanmoins de garder à l’esprit que les traitements sont effectués par l’entrepôt de données sur lequel Matillion s’appuie. Tout n’est donc pas forcement réalisable et certains projets pourront être plus intéressants à réaliser avec tel ou tel autre outil d’intégration.
De mon point de vue, les forces de la solution sont :
Du côté des points pouvant être améliorés :
Passez à la vitesse supérieure avec Matillion : cette formation vous permet d’aller plus loin dans l’intégration de données cloud avec des traitements avancés, des API et la gestion de versions.

Une formation idéale pour débuter avec Matillion : créez vos premiers workflows d’intégration de données cloud, orchestrez les traitements et manipulez vos datasets sans coder.
Accélérez vos projets data avec Matillion et ActinVision : intégration cloud-native, ETL performant et évolutif.