Article
Snowpark for Python :
fonctionnement et avantages
Rédigé par Etienne Cizeau – Consultant BI Actinvision
Snowpark est une API développée et maintenue par Snowflake depuis 2021 pour les langages de programmation Java et Scala, et depuis juin 2022 pour Python (langage que nous avons choisi d’utiliser dans ce projet).
Ce framework, en partie semblable à PySpark, permet la manipulation de données présentes au sein d’une table de données Snowflake par le biais du Python. Il permet également de déployer du code Python au sein d’une base Snowflake pour pouvoir l’exécuter par la suite. Pour ce faire, toutes les warehouses de Snowflake possèdent nativement un noyau Python permettant la compilation et l’exécution du code. Snowpark et les infrastructures de Snowflake se chargent de l’exécution du code Python et automatiquement de sa conversion en code SQL lors de la manipulation de dataframes.
Dans cet article, nous détaillerons le fonctionnement et les avantages de cet outil, et l’utiliserons avec l’exemple du jeu de données des passagers du Titanic.

Pourquoi utiliser Snowpark for Python ?
Cet outil donne accès aux principales bibliothèques de l’écosystème Python par le biais de la distribution Anaconda préinstallée sur les machines de Snowflake. Ce large éventail de bibliothèques permet d’exécuter une grande variété de projets au sein d’infrastructures distribuées, qu’il s’agisse de manipulations de tables de données par Pandas, de calculs matriciels avec Numpy, ou de visualisations de données avec Plotly ou Malplotlib.

Ecosystème Python pour le traitement de la donnée
Snowpark Python est extrêmement pertinent dans les projets Data Science puisqu’il donne accès à des bibliothèques dédiées comme Scikit-learn, XGBoost, Spacy ou encore Keras. Ces bibliothèques, qui forment la base de nombreux projets orientés data, permettent de concevoir aisément des algorithmes d’apprentissage automatique à la fois complexes et efficaces. En effet, il est possible de répondre à un grand nombre de besoins, comme le traitement du langage naturel ou l’analyse de séries temporelles, avec des méthodes variées, qu’elles soient basiques comme des arbres de décision ou complexes comme des réseaux de neurones. Toutes ces méthodes sont ainsi facilement paramétrables grâce à ces bibliothèques disponibles sur Python.
Grâce à Snowpark, il est donc possible pour un Data Scientist utilisant Python de déployer et d’exécuter son code sur les installations de Snowflake. Il est facile de déployer un modèle complexe d’apprentissage automatique, de l’entrainer, puis de le rendre utilisable par un utilisateur non-initié au Python ou à la Data Science.
Enfin, Snowpark permet de combiner les avantages du langage Python avec ceux de Snowflake, en assurant une protection et un contrôle de la donnée. Grâce à cet outil, toutes les manipulations de données se font au sein des serveurs de Snowflake sans besoin de les déplacer à l’extérieur des serveurs (comme sur une machine en local par exemple).
De plus, Il devient aisé d’intégrer ce type d’algorithme au sein d’un processus complexe traitant la donnée de bout-en-bout sur Snowflake, en utilisant un extracteur de données en amont, et un outil de visualisation en aval. Il est aussi possible d’imaginer des orchestrations complexes utilisant notre algorithme de prédiction en le réentraînant si de nouvelles données arrivent, ou à intervalle régulier, grâce aux outils d’orchestration de Snowflake, qui permettent de planifier des tâches.
Preuve de concept et dataset Titanic
Afin d’utiliser Snowpark, j’ai pu configurer sur mon ordinateur un environnement virtuel de développement composé d’un noyau Python 3.8 et de l’ensemble des bibliothèques utiles pour ce type de projet : Pandas pour la manipulation des données, et Sci-kit Learn pour la mise en place de l’algorithme d’apprentissage automatique.
Nous aborderons ici les différentes étapes du projet, à savoir : la recherche du jeu de données, le développement d’un algorithme prédictif et le déploiement du modèle.
Recherche d’un jeu de données
Dans ce projet, l’idée n’était pas de déterminer les limites de la solution mais de comprendre son principe, et quels avantages elle pourrait avoir.
Dans le but de parvenir à cet objectif, je recherchais un jeu de données simple, facile à expliquer et relativement « visuel », constituant une démonstration impactante. Je me suis donc orienté vers un des jeux de données (ou dataset) « classiques » de l’apprentissage automatique, soit le dataset Titanic.
Le but de notre algorithme sera donc de prédire la survie ou non des passagers à partir de leurs caractéristiques comme l’âge, le prix du billet ou leur classe.
Développement d’un algorithme prédictif
Après avoir choisi ce dataset, il a fallu développer un algorithme d’apprentissage automatique capable de prédire efficacement la survie des passagers du Titanic. Généralement, un projet de Machine Learning se décompose en 3 grandes parties :
L’exploration des données
Le nettoyage
La conception du modèle
Pour toutes ces étapes, j’ai utilisé la bibliothèque Sci-kit Learn disponible sur Python et ai choisi de concevoir un modèle de type Random Forest, dont les performances sont très intéressantes sur les problèmes de type classification comme celui-ci.
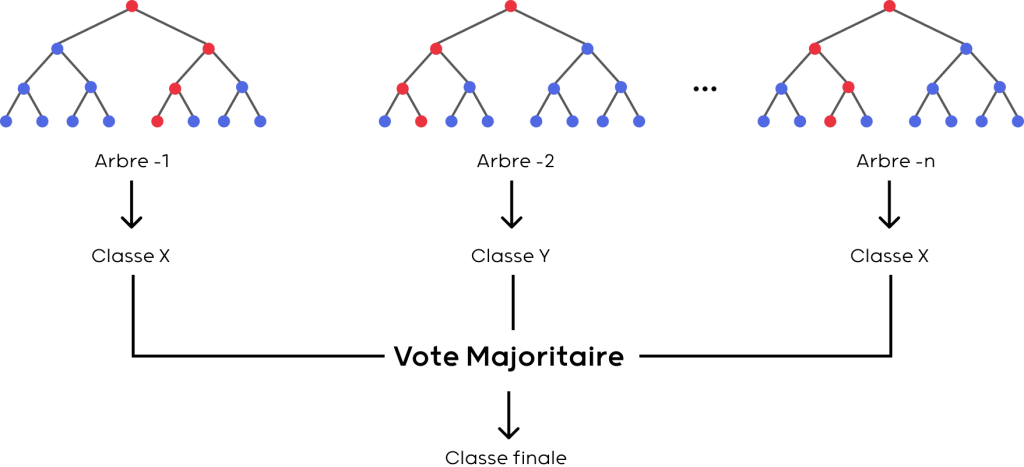
Principe de l’algorithme Random Forest
Déploiement du modèle
Après avoir conçu ce modèle, Snowpark nous permet de déployer son code afin de pouvoir entrainer un modèle similaire directement sur le cloud, et d’utiliser celui-ci au besoin. Sans rentrer dans des détails trop techniques, il suffit de prévoir un espace de stockage pour le modèle, un nom pour la procédure SQL à appeler pour entrainer le modèle, et une fonction pour pouvoir utiliser un modèle entrainé.
Une fois le modèle entrainé, il est possible de l’utiliser sur un grand nombre de données directement sur Snowflake, donc sans nécessiter de mouvement de la donnée hors du service.
Futur et projets potentiels
De nombreuses applications sont donc possibles par le biais de cet outil. En particulier, la future implémentation d’instances à haute capacité de mémoire vive, et d’instances disposant de processeurs graphiques, nous permettant d’imaginer l’utilisation de modèle encore plus complexes et ambitieux comme des réseaux de neurones.





