Les nouveautés DBT !
Article rédigé par Léo Monot – Consultant BI Actinvision
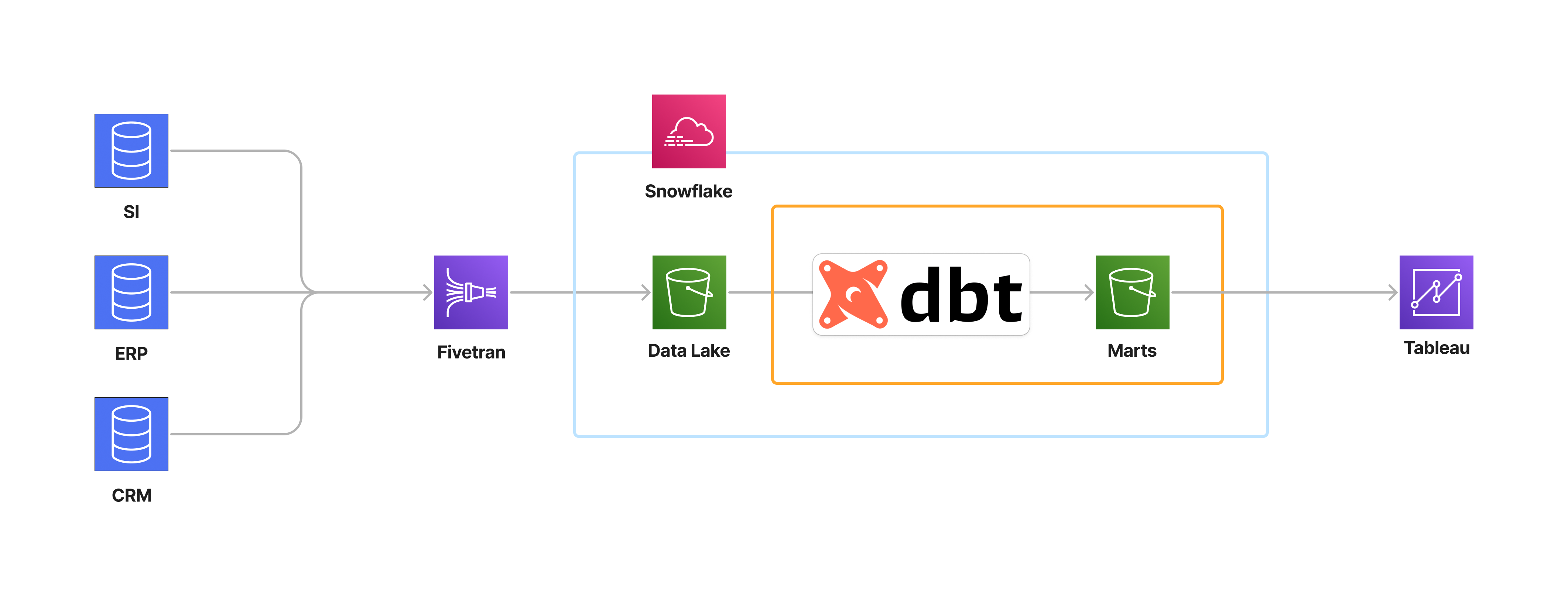
Data Build Tool ou DBT assure la transformation, qualité et gouvernance de vos données. Il représente le T dans un processus ELT. Cet outil permet de définir des procédures stockées (SQL), de les soumettre à la gestion de version (avec GIT), et de les exécuter de manière planifiée sur votre plateforme de données (Snowflake, BigQuery, Synapse, Redshift, etc.) pour obtenir desDa marts prêts à être utilisés par vos outils d’analyse (Tableau, Power BI, Looker, ThoughtSpot).
L’un des principaux avantages de DBT réside dans sa facilité d’utilisation pour la transformation des données, basée sur des requêtes SQL simples qui, mises bout à bout, forment nos pipelines de transformation de données. Cette approche rend DBT adapté aussi bien aux consultants en données qu’aux professionnels IT/Data, ainsi qu’aux utilisateurs moins techniques et plus orientés métier. En tirant parti de cette simplicité, DBT a introduit un nouveau rôle, celui d’« Analytics Engineer », qui se concentre sur la transformation (modélisation) et la restitution via un outil de reporting, travaillant en étroite collaboration avec les métiers pour les accompagner vers des opérations de données en self-service. Même sans utiliser les fonctionnalités self-service de DBT, les métiers ont accès à toute la partie gouvernance et documentation des données proposée par DBT.
Chez Actinvision, nous apprécions DBT, et l’arrivée de DBT Cloud nous a permis de déployer et de diffuser cet outil à grande échelle chez nos clients. DBT Cloud réduit la charge de travail et les compétences DevOps nécessaires au déploiement de DBT, simplifie la gestion des accès, le déploiement CI/CD, et offre une meilleure expérience utilisateur. De plus, il intègre un orchestrateur qui permet de commencer à utiliser DBT sans passer par une installation et une configuration fastidieuse d’Airflow.
Nous sommes encore plus satisfaits aujourd’hui car DBT Cloud se démarque sérieusement de sa grande sœur open source, grâce à ses nombreuses fonctionnalités natives et à ses ajouts réguliers. Passons en revue les nouveautés annoncées par l’éditeur :
DBT EXPLORER
DBT Explorer continue de progresser vers une interface de documentation et de connaissance des données recherchée par tous. Pour rappel, DBT permet de lier un développement à sa documentation, tout en la soumettant à la gestion de version. La documentation s’auto-génère à chaque exécution après une modification du projet, garantissant ainsi sa mise à jour constante. Il est ensuite possible de diffuser cette documentation via Host. Avec DBT Cloud, la documentation de vos pipelines de transformation de données est directement accessible sur le portail cloud de DBT, et le service va encore plus loin en offrant DBT Explorer, une interface d’exploration de la documentation encore plus conviviale.
LINEAGE : nouveau niveau de détail par champ
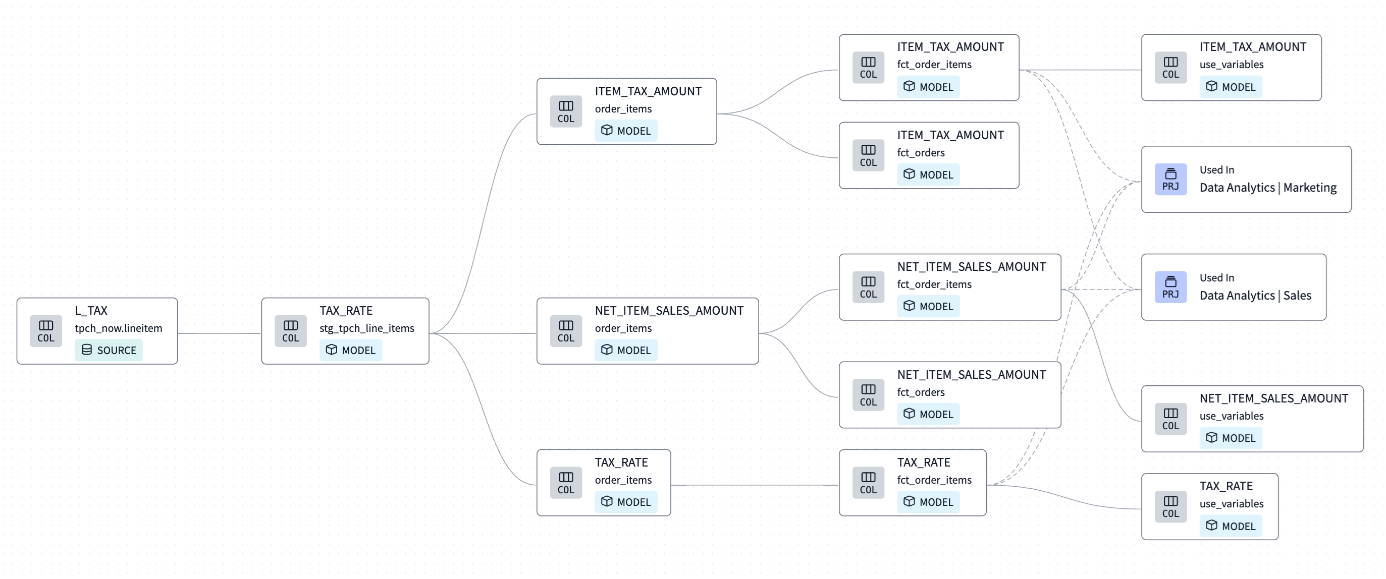
Une des fonctionnalités de la documentation de DBT est sa capacité à générer automatiquement le DAG (Directed Acyclic Graph) de vos pipelines grâce aux références et aux dépendances de chacune de vos procédures stockées (modèles SQL de DBT), permettant ainsi de naviguer, descendre et remonter dans le flux entre vos sources et vos Marts. Ce mode de navigation offre une compréhension rapide pour les métiers et les collègues nouvellement intégrés à votre contexte, tout en facilitant grandement l’investigation des problèmes de qualité des données.
Le niveau de détail du linéage s’améliore : alors qu’auparavant, nous pouvions naviguer à travers les différents modèles DBT, nous pouvons désormais inclure le champ d’un modèle dans notre navigation, et observer sa provenance source ou sa destination Mart. Ce linéage clair du champ permettra d’économiser un temps précieux lors des investigations, rendant l’utilisation du linéage extrêmement confortable. J’attendais avec impatience sur DBT Cloud l’arrivée du linéage de champs, et je suis ravi de constater cette amélioration.
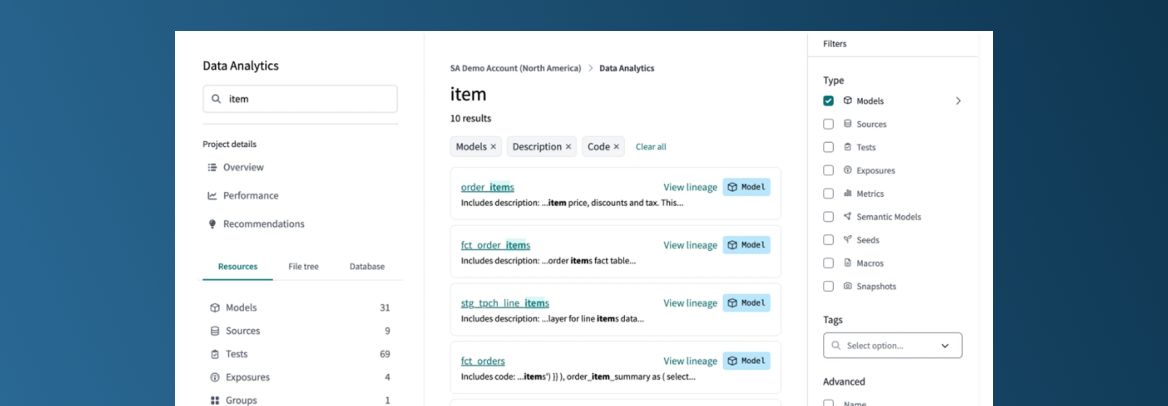
Moteur de recherche par mot clé
Le moteur de recherche par mot-clé est désormais disponible ! Auparavant, nous devions utiliser les fonctionnalités de l’IDE Visual Studio Code pour effectuer ces recherches par mots-clés dans les fichiers d’un projet DBT. Pour les utilisateurs ne faisant pas appel au Cloud CLI (Commande DBT), cette fonctionnalité de recherche par mot-clé n’était pas accessible. Cette lacune est désormais comblée de la meilleure des manières, car le moteur de recherche est parfaitement intégré dans DBT Explorer, nous permettant ainsi d’accéder aux informations documentées une fois la recherche effectuée.
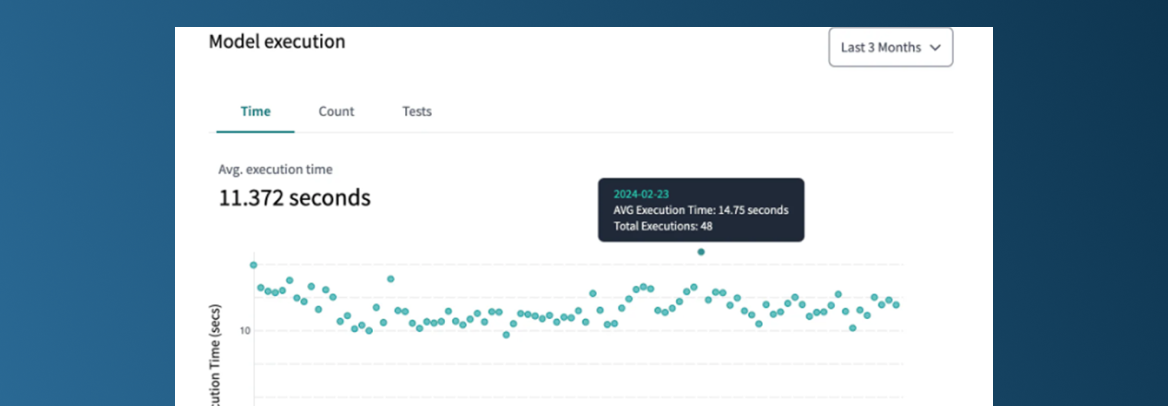
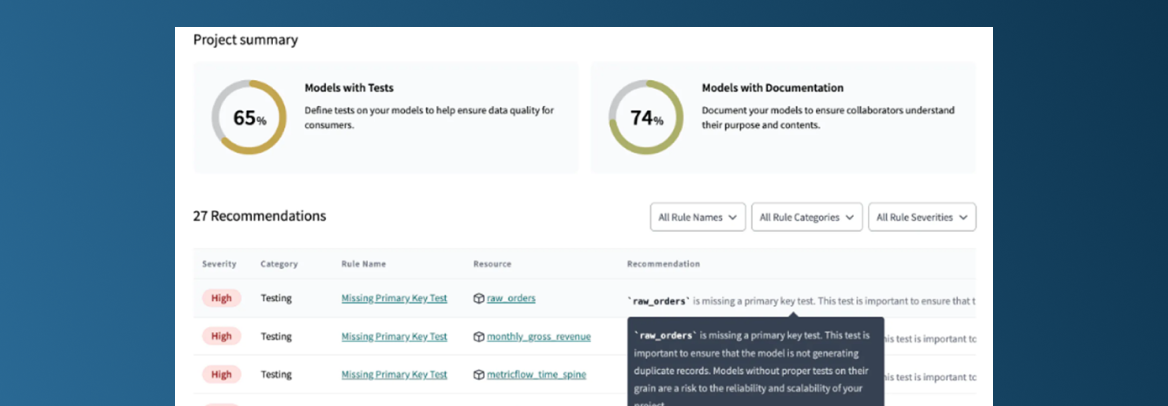
Le package
J’avais presque oublié que le project evaluator n’était pas natif, car nous l’utilisons systématiquement dans nos projets en raison des informations précieuses qu’il fournit sur la performance et la couverture de documentation de nos pipelines. DBT Cloud propose désormais une interface graphique bien plus conviviale que le format initial de texte brut du package project evaluator. Bien que les insights fournis par le project evaluator ne soient pas nouveaux, je suis convaincu que cette interface graphique augmentera considérablement l’adoption de cette solution pour l’optimisation des pipelines de données.
Au rendez-vous :
Optimisation des coûts de la plateforme de données.
Amélioration de la couverture des tests et de la documentation.
Adaptateur pour Microsoft Fabric
DBT Cloud devient nativement compatible avec Microsoft Fabric, permettant ainsi aux clients de centraliser leurs transformations et connaissances sur DBT, quelle que soit la plateforme utilisée.
Trigger Fivetran natif
DBT Core ne propose pas de service d’orchestration planifié, nous obligeant ainsi à utiliser le complexe et exigeant en compétences ops Airflow. Cependant, DBT Cloud continue d’améliorer son service d’orchestration en intégrant nativement un trigger Fivetran ! C’est une avancée majeure pour l’orchestrateur DBT Cloud, offrant une couverture quasi-totale de la chaîne décisionnelle.
Semantic Layer
Le Semantic Layer de DBT Cloud est l’élément clé de la gouvernance des données. Alors que les fonctionnalités natives de documentation offrent déjà une excellente couverture de vos pipelines de données en amont, le Semantic Layer agit comme une interface entre votre plateforme de données et vos outils d’analyse.
Il permet de décrire les entités d’une table (les identifiants), les dimensions (temps, géographie), et les mesures ainsi que leurs formules d’agrégation. Grâce au Semantic Layer, vous savez exactement quelles données vous consommez et manipulez. Cela garantit que les informations censées être identiques le sont effectivement dans les différents outils d’analyse qui consomment ces mêmes données. De plus, le Semantic Layer permet d’optimiser les performances et les coûts de calcul en exploitant le cache intégré de votre plateforme de données, notamment lorsque vous devez utiliser les mêmes données dans différents outils d’analyse.
La diffusion de ces tables du Semantic Layer se fait via API ou connecteur ODBC/JDBC, assurant ainsi une compatibilité même avec les outils d’analyse qui ne prennent pas nativement en charge DBT. Cependant, le support natif est toujours préférable, et il est désormais disponible grâce à l’arrivée d’un connecteur Tableau (Server et Desktop) !





