Article
Guide Talend Open Studio
Comment configurer des logs
Article rédigé par Nicolas Busser – Consultant BI Actinvision
Pourquoi mettre en place des logs ?
Dans tout projet d’intégration de données, il est crucial de disposer d’une visibilité sur le succès des différents flux afin d’assurer la qualité, la traçabilité et la fiabilité des différents traitements. Pour cela, il est essentiel de mettre en place une stratégie de surveillance des flux, permettant de détecter et d’identifier les éventuels problèmes pouvant affecter les traitements et nuire aux activités des clients.
L’une des stratégies, couramment utilisées pour la surveillance des flux, est l’utilisation de logs, également connue sous le nom de journaux. Les logs sont des fichiers configurés par le développeur pour enregistrer de manière chronologique les événements et les actions qui se produisent lors de l’exécution du flux d’intégration de données. Ils fournissent une trace détaillée de chaque étape du processus, ce qui facilite le dépannage, l’analyse des performances et la compréhension des erreurs éventuelles.
Comment mettre en place des logs dans Talend Open Studio ?
Talend Open Studio (TOS) est une plateforme d’intégration de données open source pour la conception, le développement et l’exécution de flux de données. Dans des cas spécifiques de cet outil, plusieurs techniques peuvent être mises en place pour mettre en œuvre des logs efficaces. Voici quelques-unes de ces techniques que nous détaillerons par la suite :
1. TALEND OPEN STUDIO permet de définir différents niveaux de log, tels que :
DEBUG,
INFO,
WARN
Ces niveaux permettent de contrôler la quantité d’informations enregistrées dans les logs. Un niveau de log DEBUG peut enregistrer des informations détaillées, tandis qu’un niveau de log ERROR peut se limiter aux erreurs critiques.
2. Il est possible de personnaliser les logs dans TALEND OPEN STUDIO en ajoutant des informations spécifiques, telles que des métadonnées sur les flux, des informations sur les transformations appliquées ou des données contextuelles. Cela permet d’enregistrer des informations supplémentaires pertinentes pour l’analyse ultérieure des logs.
3. Les logs peuvent être utilisés pour enregistrer les erreurs rencontrées lors de l’exécution du flux. Ils peuvent inclure des informations sur l’erreur elle-même, telles que le type d’erreur, le moment où elle s’est produite et les étapes du flux qui ont conduit à l’erreur. Cela facilite l’identification et la résolution des problèmes.
4. TALEND OPEN STUDIO peut être intégré à des outils de surveillance et d’analyse des logs, tels que ELK Stack (Elasticsearch, Logstash, Kibana), Splunk ou Graylog. Ces outils permettent d’agréger et de visualiser les logs de manière centralisée, facilitant ainsi la surveillance en temps réel, la recherche de données spécifiques et l’analyse des tendances. D’une grande complexité technique, la stack ELK ne sera pas vue dans cet article.
Mettre en place une stratégie de logs efficace dans Talend est la clé pour détecter rapidement les problèmes, les résoudre rapidement, et optimiser les performances. Au sein de TOS, plusieurs méthodes permettent de logger les différents flux. En dehors de la console présente dans l’outil lors des exécutions manuelles, Il n’existe pas de portail permettant d’afficher les logs générés par un flux qui serait lancé autrement, de manière automatique par exemple. En revanche, de nombreux composants sont disponibles dans la palette pour réaliser ce travail. Examinons une partie de ceux-ci.
Présentation rapide des outils
de logs contenus dans Talend
tWarm
Fais remonter un message déclencheur au tLogCatcher sans bloquer l’exécution du job principal.

tDie
Envoie un message déclencheur au tCatcher et interrompt l’exécution du job une fois qu’il est déclenché. Le message est par la suite traité par le tLogCatcher.

tLogCatcher
Ecoute le tWarm, le tDie ou d’autres commandes d’arrêt du job, comme des erreurs Java. Récupère les informations de log du message et les envoie à une sortie standard Talend.

Plusieurs choix sont possibles dans ce composant en ce qui concerne les logs à traquer :
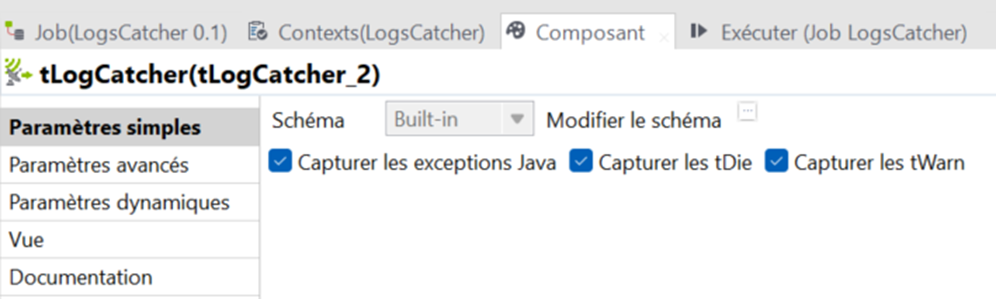
Il peut capturer les exceptions Java, les tDie et ou les tWarm. En fonction des champs sélectionnés, les messages émis par ces composants pourront être restitués ou non dans une sortie standard (fichiers, table de base de données). Le schéma utilisé pour ces 3 types de catch est identique et peut être restreint en utilisant un tMap (le schéma ne peut être mis à jour directement sur le tLogCatcher).
tFlowMeter
Mesure la volumétrie du flux à son niveau et envoie un message au tFlowMeterCatcher.

tFlowMeterCatcher
Ecoute les composants tFlowMeter et permet de compiler des informations standards de log à la sortie définie.

tChronometerStart
Démarre le calcul du temps de traitement d’un sous job

tChronometerStop
Arrête un chronomètre virtuel et permet de faire remonter la durée écoulée en tant que statistique.

tStatCatcher
Permet de capturer les statistiques d’exécution du job, y compris les durées d’exécution, le nombre de lignes traitées, les erreurs rencontrées, etc.

tAssert
Envoie un statut selon le succès (Ok) ou l’échec (Fail) du job dans lequel il est placé.

tAssertCatcher
Ecoute les tAssert ou les autres commandes Die dans le job et récupère les informations de log du message pour les envoyer dans une sortie Talend standard.

Différentes stratégies de journalisation dans Talend
De fait, plusieurs stratégies sont possibles pour journaliser les opérations d’un flux dans Talend, en utilisant les composants dédiés ou non. Examinons ces possibilités.
Utilisation du composant tLogCatcher
Le composant tLogCatcher permet de capturer les messages d’erreur ou les logs générés par les autres composants du job. Vous pouvez définir des filtres pour capturer les messages d’erreur spécifiques ou simplement capturer tous les logs. Les logs capturés peuvent ensuite être écrits dans un fichier ou envoyés à une base de données, un système de gestion des logs ou tout autre système de stockage.
Avantages
Capture des logs d’erreur : vous pouvez capturer les messages d’erreur générés par les composants du job, ce qui facilite le débogage.
Gestion centralisée des logs : vous pouvez stocker les logs capturés dans un fichier, une base de données ou tout autre système de stockage centralisé.
Flexibilité : vous pouvez définir des filtres pour capturer uniquement les logs pertinents, ce qui permet de réduire le volume de logs à gérer.
Inconvénients
Configuration initiale nécessaire : vous devez configurer correctement le composant tLogCatcher pour capturer les logs souhaités. Cela inclus un grand nombre de composant tDie et tWarn pouvant alourdir la structure des jobs.
Surcharge de traitement : si le volume de logs est élevé, la capture de tous les logs peut entraîner une surcharge de traitement et affecter les performances globales du job.
Utilisation du tFlowMeter (et catcher)
Le composant tFlowMeter permet de mesurer et de contrôler le débit des données à différentes étapes du job.
Avantages
Mesure du débit des données : vous pouvez suivre le débit des données à différentes étapes du job pour identifier les éventuels goulets d’étranglement ou les problèmes de performance.
Contrôle du débit : vous pouvez définir des seuils de débit et prendre des mesures appropriées si les seuils sont dépassés.
Possibilité de filtrage : vous pouvez mesurer le débit pour des flux de données spécifiques ou appliquer des filtres pour mesurer uniquement certaines données.
Inconvénients
Configuration initiale nécessaire : vous devez configurer correctement le tFlowMeter pour mesurer le débit souhaité.
Surcharge de traitement : la mesure du débit peut ajouter une surcharge de traitement, en particulier si vous mesurez le débit à plusieurs endroits du job ou si le volume de données est important.
Il est important de noter que le tFlowMeter est principalement destiné à la capture de statistiques et de mesures de performance. Il peut compléter les autres méthodes de création de logs dans Talend Open Studio, mais ne fournissent pas de logs détaillés sur les données elles-mêmes.
Utilisation du tStatCatcher
Le composant tStatCatcher permet de capturer les statistiques d’exécution du job, y compris les durées d’exécution, le nombre de lignes traitées, les erreurs rencontrées, etc.
Avantages
Capture des statistiques d’exécution : vous pouvez obtenir des informations précises sur les performances de votre job, y compris les temps d’exécution et les statistiques de traitement.
Gestion centralisée des statistiques : vous pouvez stocker les statistiques capturées dans un fichier, une base de données ou tout autre système de stockage centralisé.
Possibilité de filtrage : vous pouvez définir des filtres pour capturer uniquement les statistiques pertinentes.
Inconvénients
Configuration initiale nécessaire : vous devez configurer correctement le tStatCatcher pour capturer les statistiques souhaitées.
Surcharge de traitement : si vous capturez de nombreuses statistiques, cela peut entraîner une surcharge de traitement et affecter les performances globales du job.
Il est important de noter que le tStatCatcher est principalement destiné à la capture de statistiques et de mesures de performance. Il peut compléter les autres méthodes de création de logs dans Talend Open Studio, mais ne fournissent pas de logs détaillés sur les données elles-mêmes.
Utilisation du tLogRow
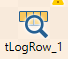
Le composant tLogRow permet d’afficher les lignes de données sur la console lors de l’exécution du job. Vous pouvez connecter ce composant à la sortie de n’importe quel autre composant pour afficher les données qui le traversent.
Avantages
Facilité d’utilisation : le composant tLogRow est simple à configurer et à utiliser.
Affichage en temps réel : les logs sont affichés directement dans la console pendant l’exécution du job, ce qui permet un suivi immédiat.
Convient aux logs de petite taille : cette méthode est appropriée lorsque vous souhaitez afficher uniquement quelques lignes de données à des étapes spécifiques du job.
Inconvénients
Pas de persistance des logs : les logs ne sont pas enregistrés dans un fichier ou une base de données, ce qui rend difficile la consultation des logs après l’exécution du job.
Difficulté de gestion des logs volumineux : si vous générez de nombreux logs, il peut être difficile de les suivre dans la console, surtout lorsque l’exécution du job est rapide.
Aucune normalisation : les logs auront la forme de leur flux respectif, empêchant de facilement normaliser les différents logs pour des jobs distincts.
Utilisation de fonctions Java de logging

Enfin, il est possible d’utiliser des expressions Java dans les composants Talend pour afficher des logs en utilisant la fonction System.out.println(). Cette méthode est utile pour afficher des messages personnalisés ou des valeurs de variables à des étapes spécifiques du job.
Avantages
Flexibilité totale : vous pouvez afficher des messages personnalisés ou des valeurs de variables à des étapes spécifiques du job, au sein même du code !
Simplicité : cette méthode utilise des expressions Java standard, ce qui la rend facile à utiliser.
Inconvénients
Logs mélangés avec les autres messages de la console : les logs affichés avec System.out.println() sont mélangés avec les autres messages de la console, ce qui peut rendre la lecture des logs plus difficile.
Difficulté de gestion des logs volumineux : si vous générez de nombreux logs, il peut être difficile de les suivre dans la console, surtout lorsque l’exécution du job est rapide.
Pas de persistance des logs : ils ne sont pas enregistrés dans un fichier ou une base de données, ce qui rend difficile la consultation des logs après l’exécution du job.
Changement de paradigme : le débogage via des sondes java demande à passer d’un paradigme intégration à celui d’un développeur java, ce qui peut rendre difficile la maintenabilité du projet.
Gestion log globale
Génère automatiquement un traitement des logs en fin de chargement (sans avoir à définir de fichier de sortie dans chaque job), Cette méthode traquera sur le projet/job tous les tWarm, tDie et Error java, (= tLogCatcher : en revanche, parmis ces 3, impossible à ce niveau de pouvoir choisir lesquels spécifiquement restituer, ils remonteront tous dans les cibles définies) ou tStatCatcher et tFlowMeterCatcher.
Paramètre des logs possible au niveau du projet
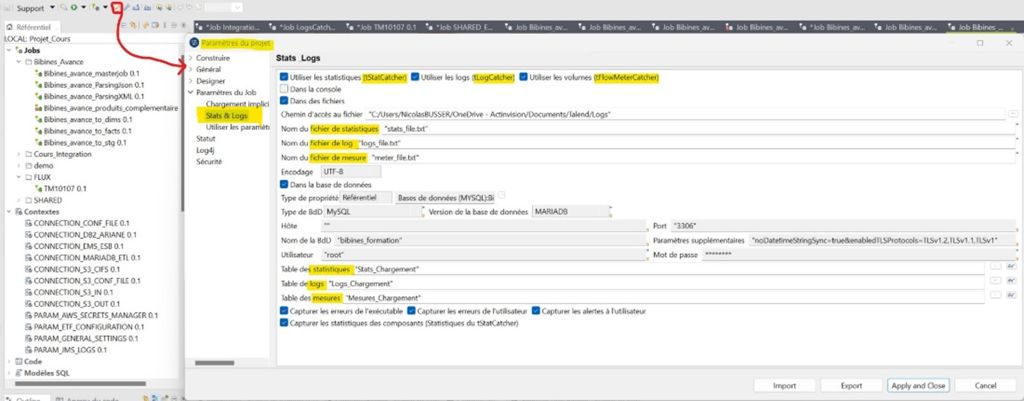
Il est possible de configurer des paramètres de tCatch à partir des propriétés du projet et ainsi regrouper au même endroit tous les tCatch du projet
Gestion des Logs possible au niveau d’un job en particulier
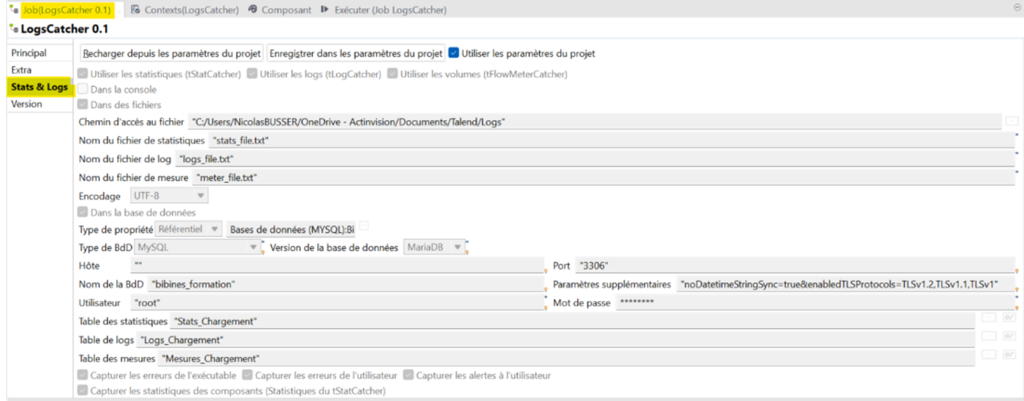
Dans l’onglet rattaché au job, celui-ci peut récupérer le format défini pour le projet si celui-ci est renseigné, ou peut aussi posséder une configuration qui lui est propre pour une analyse ponctuelle d’un job en particulier.
ATTENTION, si un log job est spécifié et que sa configuration est différente de la configuration du projet, celle-ci sera exécutée en priorité pour ce job à la place de celle du projet. En revanche, si une sortie est définie dans le flux de chargement à l’aide d’un tLogCatcher, celle-ci sera en complément de l’action définie dans la configuration du Job/Projet (2 sorties de logs seront ainsi utilisées).
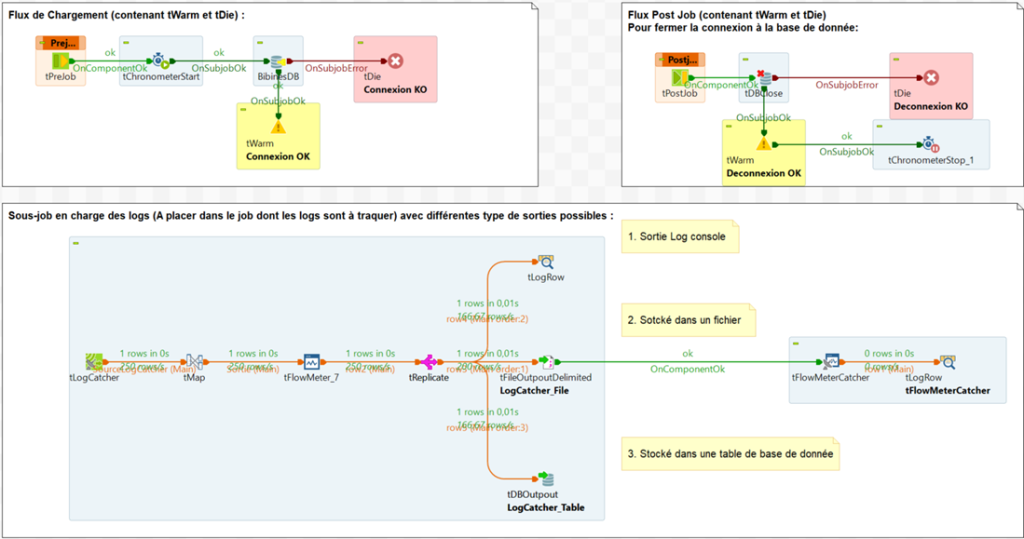
Test du flux journalisé
Exemple : Mise en place de logs via tDie/tWarn dans TOS
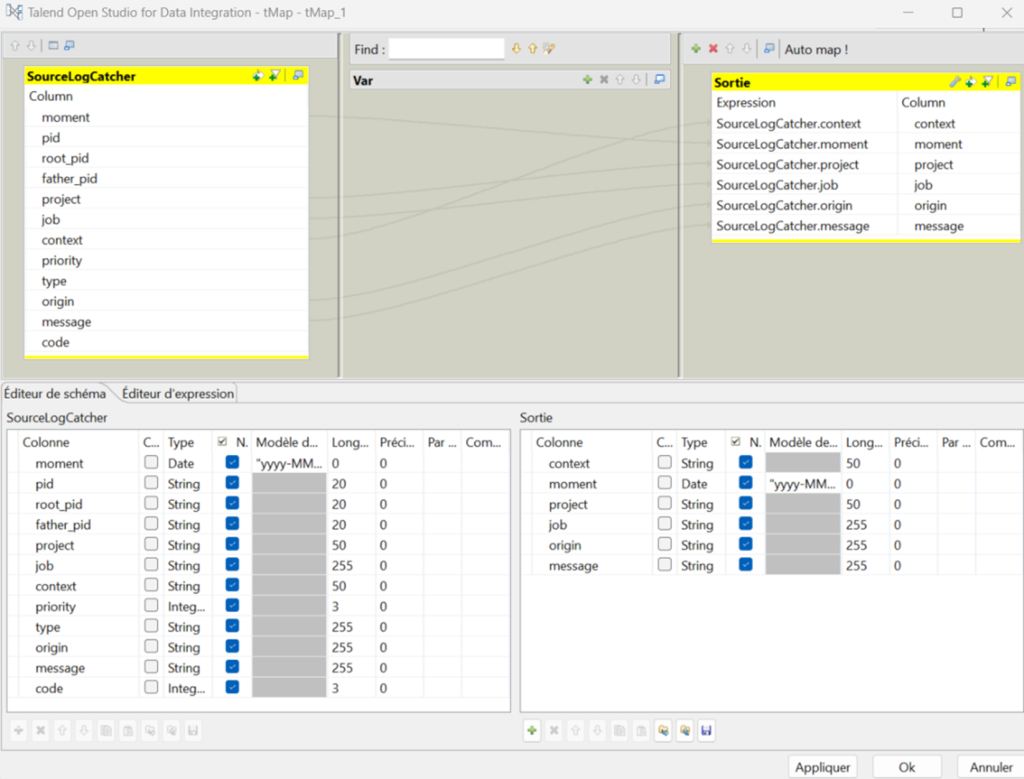
Restitution du log possible à choisir dans un tMap issue d’un tLogCatcher
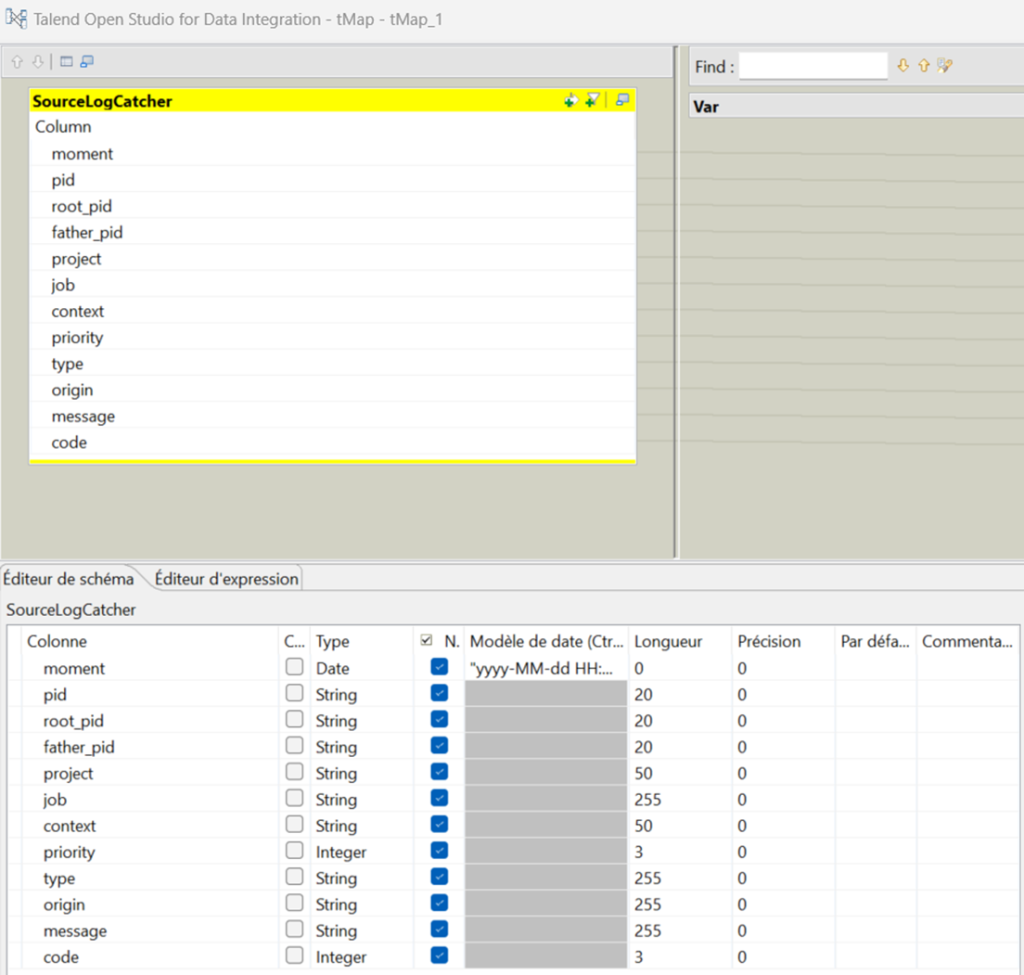
Exemple de restitution du tLogCatcher
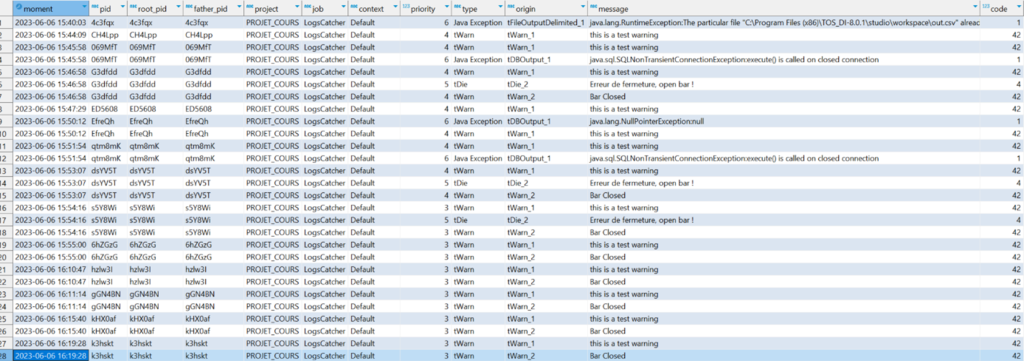
Colonnes pouvant être utilisées de manière pertinente dans un log d’exécution pour restitutions : Context, Moment, Project, Job, Code, Origine, Message
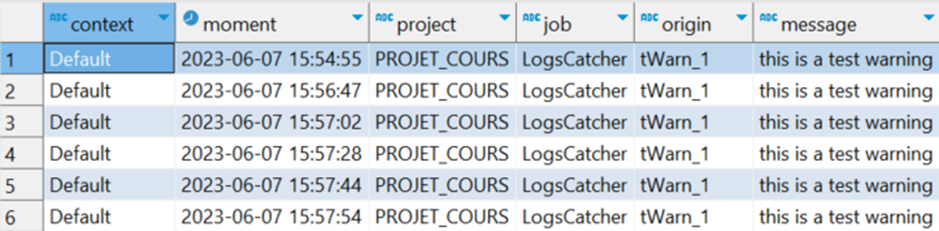
Obtenu sur notre job d’exemple Via le tMap suivant après le tLogCatcher, ou alors à extraire à partir de la table ou fichier centralisé des logs (traitement qui sera à mettre en place)
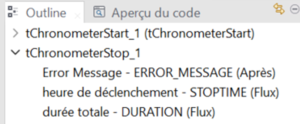
Le flux de chargement possède à son lancement un tChronometrStart ainsi qu’un tChronometerStop à la fin du flux. Celui-ci peut aussi être récupérable grâce aux variables Outline.