Written by Etienne Cizeau – ActinVision BI Consultant
Snowpark is an API developed and maintained by Snowflake since 2021 for the Java and Scala programming languages, and since June 2022 for Python (the language we have chosen to use in this project).This framework, similar in part to PySpark, enables the manipulation of data present in a Snowflake data table via Python. It also enables Python code to be deployed within a Snowflake database for subsequent execution.To this end, all Snowflake warehouses are natively equipped with a Python kernel, enabling code compilation and execution. Snowpark and Snowflake infrastructures take care of executing the Python code and automatically converting it into SQL code when dataframes are manipulated.
In this article, we’ll take a look at how this tool works and its advantages, and use it with the example of the Titanic passenger dataset!
This tool provides access to the main libraries of the Python ecosystem via the Anaconda distribution pre-installed on Snowflake machines.This wide range of libraries makes it possible to run a wide variety of projects within distributed infrastructures, from data table manipulations with Pandas, matrix calculations with Numpy, to data visualization with Plotly or Malplotlib.
Python ecosystem for data processing
Snowpark Python is highly relevant to Data Science projects, providing access to dedicated libraries such as Scikit-learn, XGBoost, Spacy and Keras. These libraries, which form the basis of many data-oriented projects, make it easy to design machine learning algorithms that are both complex and efficient. Indeed, it is possible to meet a wide range of needs, such as natural language processing or time series analysis, with a variety of methods, from basic ones like decision trees to complex ones like neural networks. All these methods can be easily parameterized thanks to the libraries available in Python.
Thanks to Snowpark, it is now possible for a Data Scientist using Python to deploy and run his code on Snowflake installations. It’s easy to deploy a complex machine learning model, train it, and then make it usable by a user unfamiliar with Python or Data Science.
Finally, Snowpark combines the advantages of the Python language with those of Snowflake, ensuring data protection and control. Thanks to this tool, all data manipulation takes place within the Snowflake servers, without the need to move it outside the servers (as on a local machine, for example).
What’s more, it’s easy to integrate this type of algorithm into a complex end-to-end data processing process on Snowflake, using an upstream data extractor and a downstream visualization tool. It is also possible to imagine complex orchestrations using our prediction algorithm, re-training it if new data arrives, or at regular intervals, thanks to Snowflake’s orchestration tools, which enable tasks to be scheduled.
Proof of concept and Titanic dataset
In order to use Snowpark, I was able to set up a virtual development environment on my computer, consisting of a Python 3.8 kernel and all the libraries needed for this type of project: Pandas for data manipulation, and Sci-kit Learn for setting up the machine learning algorithm.
In this section, we’ll look at the various stages of the project: dataset research, development of a predictive algorithm and model deployment.
Dataset search
In this project, the idea was not to determine the limits of the solution, but to understand its principle, and what advantages it might have.
In order to achieve this goal, I was looking for a simple, easy-to-explain and relatively “visual” dataset that would make an impactful demonstration. I therefore turned to one of the “classic” machine learning datasets, the Titanic dataset.
The aim of our algorithm will therefore be to predict whether or not passengers will survive, based on their characteristics such as age, ticket price or class.
Development of a predictive algorithm
Once this dataset had been selected, it was necessary to develop a machine learning algorithm capable of effectively predicting the survival of the Titanic’s passengers. Typically, a Machine Learning project breaks downinto 3 main parts:
Data mining
Cleaning
Model design
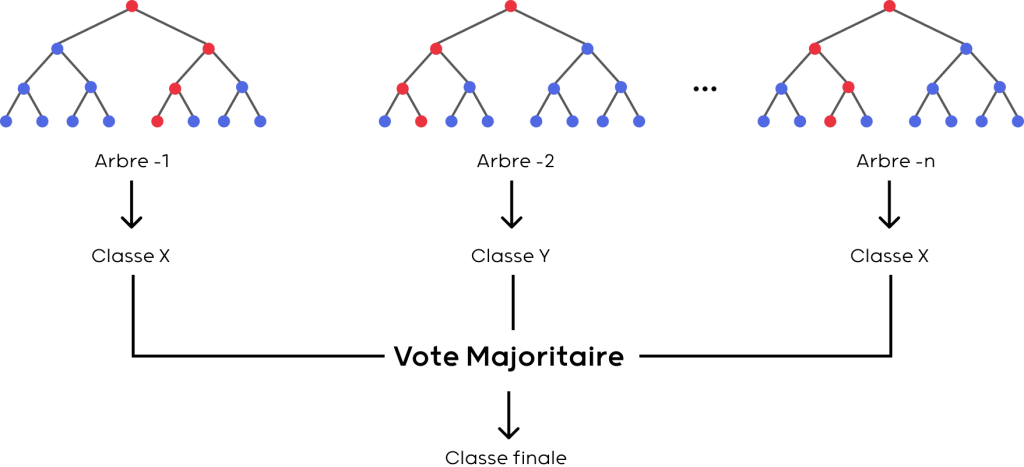
For all these steps, I used the Sci-kit Learn library available on Python and chose to design a Random Forest model, whose performance is very interesting on classification-type problems like this one.
Principle of the Random Forest algorithm
Model deployment
Once we’ve designed this model, Snowpark lets us deploy its code so that we can train a similar model directly on the cloud, and use it as needed. Without going into too much technical detail, all we need is a storage space for the model, a name for the SQL procedure to be called to train the model, and a function to be able to use a trained model.
Once the model has been trained, it can be used on a large number of data sets directly in Snowflake, without having to move the data out of the service.
Future and potential projects
Many applications are therefore possible with this tool. In particular, the future implementation of instances with high RAM capacity, and instances with graphics processors, will enable us to imagine the use of even more complex and ambitious models such as neural networks.