Article written by Léo Monot – ActinVision BI Consultant
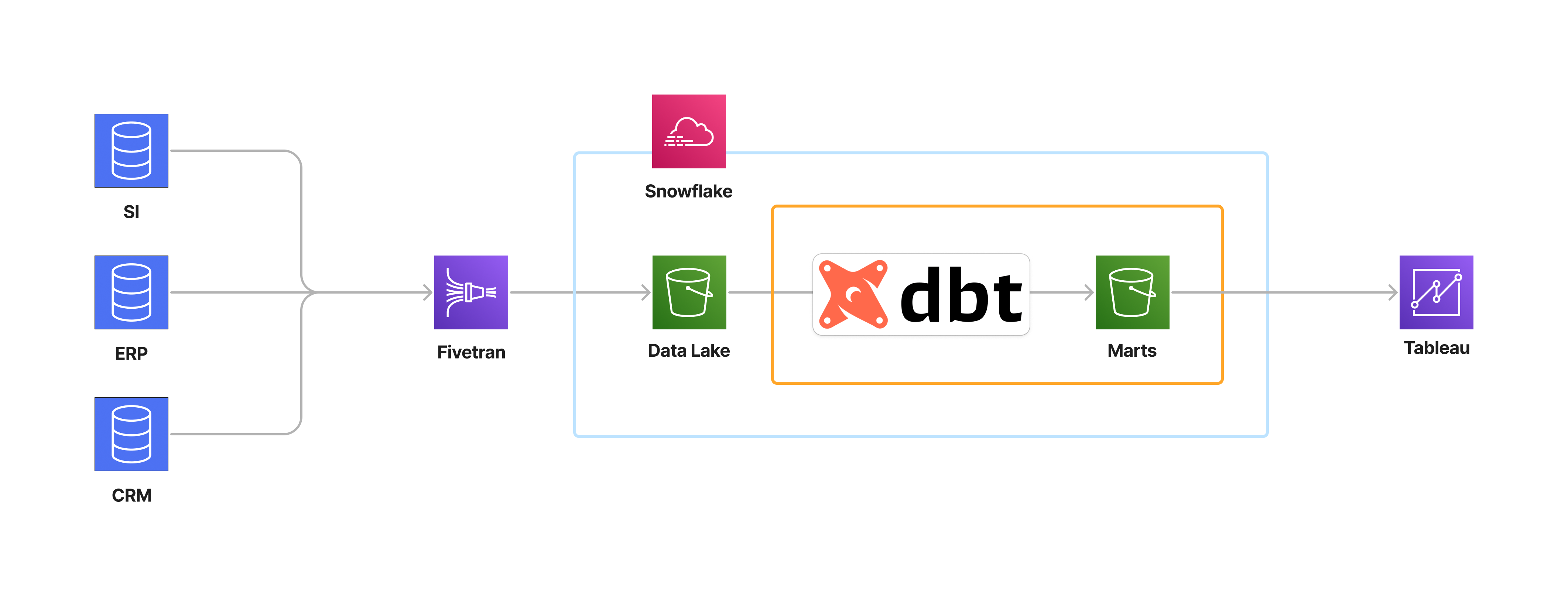
Data Build Tool or DBT ensures the transformation, quality and governance of your data. It represents the T in an ELT process. This tool enables you to define stored procedures (SQL), submit them to version management (with GIT), and execute them in a scheduled manner on your data platform (Snowflake, BigQuery, Synapse, Redshift, etc.) to obtain Datamarts ready for use by your analysis tools (Tableau, Power BI, Looker, ThoughtSpot).
One of DBT’s key advantages is its ease of use for data transformation, based on simple SQL queries which, when put together, form our data transformation pipelines. This approach makes DBT suitable for both data consultants and IT/Data professionals, as well as less technical and more business-oriented users. Leveraging this simplicity, DBT has introduced a new role, that of “Analytics Engineer”, who focuses on transformation (modeling) and restitution via a reporting tool, working closely with the business to support them towards self-service data operations. Even without using DBT’s self-service functionalities, business users have access to all the data governance and documentation services offered by DBT.
At ActinVision, we like the DBT tool, and the arrival of DBT Cloud has enabled us to deploy and disseminate this tool on a large scale among our customers. DBT Cloud reduces the workload and DevOps skills required to deploy DBT, simplifies access management and CI/CD deployment, and offers a better user experience. What’s more, it incorporates an orchestrator that lets you start using DBT without going through the tedious process of installing and configuring Airflow.
We’re even happier today, as DBT Cloud stands out from its open source sibling, thanks to its many native features and regular additions. Let’s take a look at the new features announced by the publisher:
DBT Explorer
DBT Explorer continues to make progress towards the documentation and data knowledge interface that everyone is looking for. As a reminder, DBT makes it possible to link a development to its documentation, while subjecting it to version management. Documentation is auto-generated each time the project is run after a modification, ensuring that it is constantly updated. This documentation can then be distributed via Host. With DBT Cloud, the documentation of your data transformation pipelines is directly accessible on the DBT cloud portal, and the service goes even further by offering DBT Explorer, an even more user-friendly documentation exploration interface.
LINEAGE: new level of detail by field
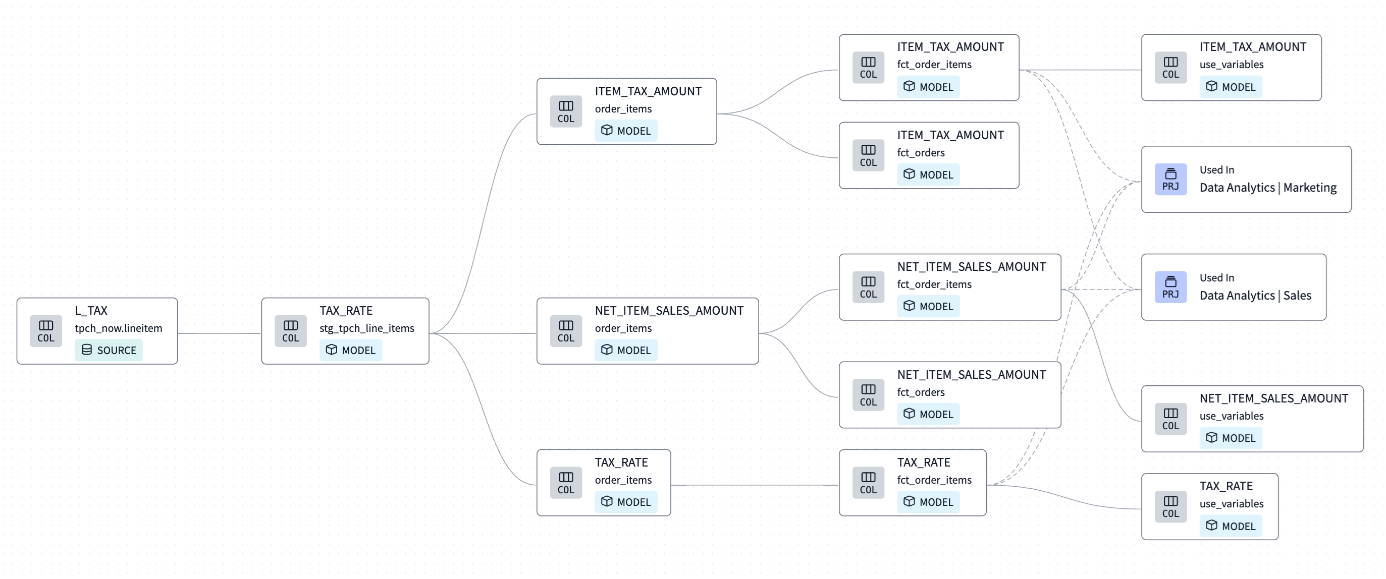
One of DBT’s documentation features is its ability to automatically generate the DAG (Directed Acyclic Graph) of your pipelines thanks to the references and dependencies of each of your stored procedures (DBT’s SQL models), enabling you to navigate up and down the flow between your sources and your Marts. This navigation mode offers rapid comprehension for businesses and colleagues newly integrated into your context, while greatly facilitating the investigation of data quality issues.
The level of detail in lineage has improved: whereas previously we could navigate through the various DBT models, we can now include a model’s field in our navigation, and observe its source provenance or Mart destination. This clear linearization of the field will save precious time during investigations, making the use of linearization extremely comfortable. I’ve been looking forward to the arrival of field linearization on DBT Cloud, and I’m delighted to see this improvement.
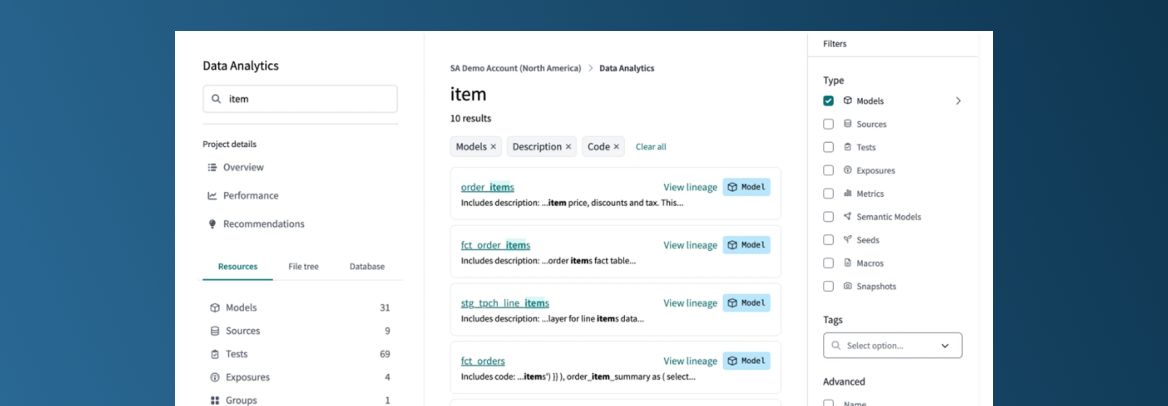
Keyword search engine
The keyword search engine is now available! Previously, we had to use the Visual Studio Code IDE to perform these keyword searches in DBT project files. For users not using the Cloud CLI (DBT Command), this keyword search functionality was not accessible. This gap is now filled in the best possible way, as the search engine is seamlessly integrated into DBT Explorer, enabling us to access documented information once the search has been carried out.
The package
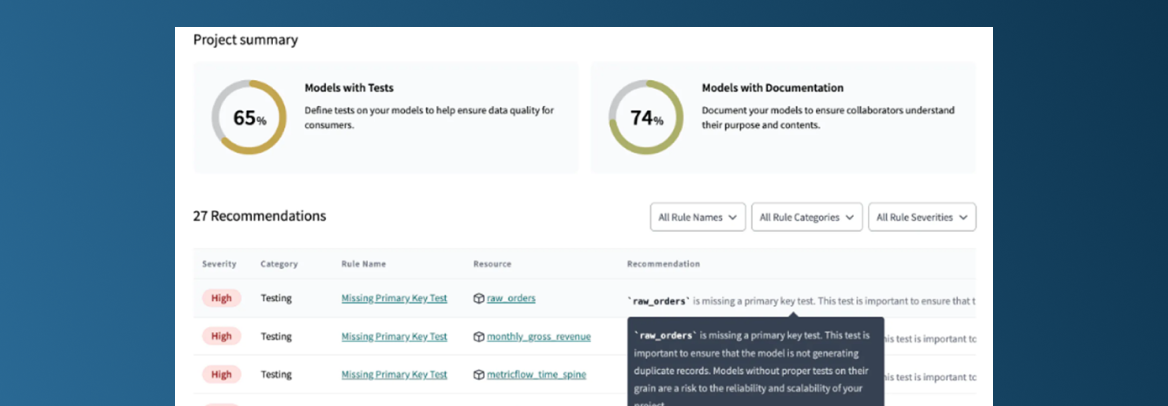
I’d almost forgotten that the project evaluator wasn’t native, as we use it systematically in our projects because of the valuable information it provides on the performance and documentation coverage of our pipelines. DBT Cloud now offers a much more user-friendly graphical interface than the original plain text format of the project evaluator package. Although the insights provided by the project evaluator are not new, I am convinced that this graphical interface will significantly increase the adoption of this solution for data pipeline optimization.
On the agenda:
Optimization of data platform costs.
Improved test coverage and documentation.
Adapter for Microsoft Fabric
DBT Cloud becomes natively compatible with Microsoft Fabric, enabling customers to centralize their transformations and knowledge on DBT, whatever platform they use.
Trigger Fivetran native
DBT Core doesn’t offer a scheduled orchestration service, forcing us to use the complex and skill-intensive Airflow ops. However, DBT Cloud continues to improve its orchestration service by natively integrating a Fivetran trigger! This is a major advance for the DBT Cloud orchestrator, offering almost complete coverage of the BI chain.
Semantic Layer
DBT Cloud’s Semantic Layer is the key element in data governance. While native documentation features already provide excellent coverage of your upstream data pipelines, the Semantic Layer acts as an interface between your data platform and your analysis tools.
It allows you to describe table entities (identifiers), dimensions (time, geography) and measures, as well as their aggregation formulas. Thanks to the Semantic Layer, you know exactly what data you’re consuming and manipulating. This ensures that information that is supposed to be identical is in fact identical in the different analysis tools that consume the same data. What’s more, the Semantic Layer enables you to optimize performance and computing costs by exploiting your data platform’s built-in cache, particularly when you need to use the same data in different analysis tools.
These Semantic Layer tables are distributed via API or ODBC/JDBC connector, ensuring compatibility even with analysis tools that don’t natively support DBT. However, native support is always preferable, and it’s now available thanks to the arrival of a Tableau connector (Server and Desktop)!