Dossier
IOT Data Streaming
avec Kafka & Snowflake
Rédigé par Rudy Krauffel – Consultant Actinvision
Le nombre des objets connectés dit « IoT » est en augmentation rapide : on estime leur nombre à près de 8 milliards en 2019, avec une prévision qui dépasse les 24 milliards en 2030 (source : Transforma Insights).
Les données que ces objets connectés génèrent permettent aux différents acteurs d’accéder à une compréhension nouvelle de leurs secteurs d’application. En logistique, ils peuvent aussi bien rendre possible une gestion des stocks précise, qu’un monitoring des conditions atmosphériques de l’entrepôt, souvent critique pour certaines marchandises. Dans un autre scénario, un agriculteur pourra lui guider son travail grâce à l’apport d’une connaissance totale des conditions hygrométriques de ses parcelles, complétant les données météorologiques à sa disposition.
Ces données n’ont un intérêt et une plus-value que si elles sont remontées rapidement aux utilisateurs pour rendre possibles des actions rapides. L’exploitation de ces données devient alors un avantage compétitif considérable.
Data Streaming
Traditionnellement les données sont récupérées d’une source puis chargées dans une cible de manière périodique sous la forme de chargement batch, typiquement toutes les 24H en utilisant un outil de type ETL ou un outil de réplication. Ce mode perd en efficacité lorsque nous nous intéressons à des données IOT.
Le data streaming a pour objectif d’envoyer (faire un push) de la donnée dès qu’elle est générée en source de manière continue et asynchrone. La création de la donnée devient également le déclencheur de sa propagation en cible. Ceci permet de traiter des flux de données avec une forte fluctuation des volumes et de les remonter rapidement mais surtout de manière continue. De cette manière il n’est plus nécessaire de répéter des extractions à des fréquences élevées pour s’assurer que la donnée soit remontée.
Le temps réel est un cas particulier du data streaming où l’objectif sera de réduire le temps entre la génération de la donnée et son utilisation à zéro. Cette instantanéité est indispensable pour une alerte de niveau par exemple.
Dans notre exemple, nous allons nous focaliser sur une solution cloud de data streaming scalable, robuste, simple à implémenter et à maintenir qui permet de rapidement ( < 3 min ) récupérer, transformer et stocker les données dans un entrepôt de données cloud pour permettre des analyses et des croisements avancées avec les autres données de l’entreprise. Le stockage et la facilité d’analyse postérieures sont privilégiés au traitement temps réel, de type notification ou alerte, où d’autres technologies seraient plus appropriées.
PoC : Intégration continue de données IoT
Pour démontrer la simplicité de mise ouvre et la robustesse de Snowflake et son connecteur Kafka nous avons réalisé pour un PoC en combinant :
- Capteurs IoT branchés sur une Raspberry Pi
- Confluant Kafka – Une plateforme de streaming de données distribuée
- Snowflake – La plateforme data cloud qui vous permets d’adresser la majorité des usages d’exploitation de la données en entreprise mais aussi aller au-delà et se connecter au « Data cloud Snowflake »
Le choix du Raspberry Pi n’est pas fortuit. A l’heure actuelle, ces machines abordables sont parmi les plus utilisées pour le prototypage et l’implémentation de l’IoT en production, partout dans le monde. Du monitoring au pilotage, en passant par le rôle de gateway, les single board computers (SBC) sont aujourd’hui le fer de lance de l’IoT. Ils sont abordables, compacts, puissants et connectés : autant de facteur clés pour rendre un appareil propice à l’IoT.
Kafka, au sein de la plateforme Confluent, est un choix évident pour la mise en place de manière simplifiée d’un service de messages. Disponible en version On-Premise comme en version cloud, Confluent met a disposition une plateforme de streaming de messages permettant le transfert d’un très gros volume de données s’appuyant sur Kafka.
Le choix entre Confluent cloud et Confluent On-Premise dépendra avant tout de l’infrastructure déjà disponible a priori. Bien qu’elle offre une configuration plus poussée, la solution On-Premise est plus couteuse de par les frais occasionnés par la machine qu’elle occupe, ainsi que le temps à la mettre en place. Selon nos estimations, dans un scénario d’envoi de 300 000 messages par jour (environ 300Mo), le prix de revient mensuel du flux de données est de 120€ pour Confluent OP, et de 56€ pour la version Cloud Basic dans la version la plus économique. La tarification de Confluent Cloud est largement proportionnelle au volume des données et au temps de fonctionnement du Snowflake Connector : on peut donc estimer, dans notre scénario, que les coûts des deux solutions s’égalisent à environ 1Go de données quotidiennes. L’avantage évident de la solution cloud est son utilisation en SaaS et sa scalabilité.
Quant à Snowflake, cette plateforme dont la popularité ne cesse de croitre et s’impose comme référence pour les usages data à forte volumétrie. C’est également un choix évident pour qui cherche fiabilité, scalabilité et puissance. Fondée en 2012 et aujourd’hui catégorisée comme leader par Gartner dans le domaine des solutions de management et d’analyse de données (aux côtés de Google, Microsoft et AWS sur lesquelles elle s’appuie), la plateforme Data s’impose en 2021 comme un acteur inévitable du traitement et du warehousing de données dans le Cloud. Les capacités de cette solution s’articulent parfaitement avec nos objectifs de stockage et de streaming de données IoT, notamment en termes d’automatisation du parsing de message.
Architecture du flux continu
Pour réaliser ce PoC nous avons cherché une architecture simple qui permet d’ingérer efficacement et rapidement ce type de données et les rendre disponibles pour les analyser et ceci de manière continue.
Nous avons ainsi combiné l’utilisation de Confluent Kafka, du connecteur Sink Kafka réalisé en partenariat avec Snowflake, et de la plateforme Snowflake avec ses différents services complètement intégrés (stream, task) pour réaliser notre architecture de flux continu.
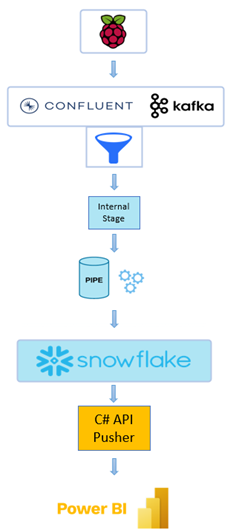
Pour ce Proof-of-Concept, nous avons choisi d’utiliser Kafka pour la collecte des données dans un message queue, et Snowflake pour leur stockage final. Ce flux de données intégralement traité dans le Cloud permet de s’affranchir des contraintes de stockage et de puissance des solutions On-Premise.
Kafka est un MOM, un message-oriented middleware. Il permet à des publicateurs d’envoyer des messages dans des topics, où ils attendent d’être récupérés par les abonnés de ces topics. Le format des messages n’est pas important pour Kafka, mais le client final du flux de données peut lui imposer des restrictions de format. Le sync connecteur Kafka vers Snowflake par exemple n’accepte que les messages JSON ou Avro. Un message dans un autre format ne pourra pas être récupéré avec succès avec ce connecteur.
Snowflake est une plateforme cloud de traitement et de stockage de données. Ses principaux atouts sont son incroyable scalabilité, ainsi que sa capacité à travailler sur et avec les trois principaux fournisseurs de cloud storage et compute : Google, Amazon et Microsoft.
Sur la Raspberry Pi, un programme est lancé, prenant en paramètres le nombre de messages et l’intervalle auquel les envoyer. A chaque itération, un fichier JSON contenant les données est généré et envoyé à Kafka vers un topic nommé ‘rpi’. Sur Kafka, un connecteur est paramétré pour absorber les messages arrivant sur ce topic : il s’agit du connecteur SnowflakeSinkConnector.
Il est important de mettre l’accent sur la simplicité de la configuration de ce connecteur. Le Sink Connector n’a besoin que d’un utilisateur Snowflake et des informations de connexion à l’instance Snowflake. Il est ensuite totalement autonome pour absorber les messages du topic, créer la table d’ingestion des données portant le nom du topic, déposer les messages dans un stage interne sur Snowflake, créer un Snowpipe et utiliser ce service serverless de Snowflake pour charger les données dans la table d’ingestion. Cette table contient alors une ligne pour chaque message en tirant profit de la capacité de snowflake à héberger nativement des données semi structurées, en l’occurrence du JSON dans notre exemple. .
Pour être utile, il faut que ce message soit parsé et que températures, dates, tensions, soient séparés en colonnes individuelles. Snowflake, à l’aide d’une syntaxe spécifique, est capable de requêter les données au format JSON, et ainsi les mettre en table classique. Pour automatiser cette tâche, les fonctionnalités Stream et Task de Snowflake sont toutes désignées. Stream surveille et enregistre les opérations de DML sur la table d’ingestion ‘RPI’, c’est-à-dire toutes les nouvelles arrivées de message, et Task observe le Stream pour savoir si de nouvelles données sont disponibles pour être traitées. A intervalles réguliers, la Task va requêter chaque nouveau JSON arrivé dans RPI et référencé dans le Stream, et insérer les données qu’il contient dans une table où les données deviennent utilisables. Quand la transaction est achevée, le Stream est vidé. L’arrivée des messages suivant sur la table ‘RPI’ déclenchera le prochain cycle et ainsi, nos données seront toujours traitées et insérées en table automatiquement à l’avenir.
La dernière étape consiste à amener ces données fraiches dans un outil de visualisation capable de se mettre à jour de manière autonome pour toujours afficher les dernières données. Pour cela, nous avons programmé un connecteur dont le rôle est d’interroger Snowflake sur ses dernières données, pour les envoyer vers un dashboard Power BI. Le célèbre outil de Microsoft dispose d’un fonctionnalité très utile dans notre cas d’usage : les jeux de données de streaming. Ils offrent un endpoint API auquel connecter notre programme, et les visuels y étant adossés se voient mis-à-jour automatiquement.
Toutes ces technologies s’articulent avec élégance pour obtenir un flux de données stable et rapide, permettant de stocker les données mais aussi de les visualiser dès leurs présence en base de données.
Conclusion
Ce flux de données automatisé, de la collecte à la table finale, démontre la performance et l’élégance des solutions hébergées dans le cloud pour le traitement des données IoT. Dans le scénario de notre Proof of Concept, les données générées par le Raspberry Pi (capteurs de luminosité de température etc) mettent moins d’une minute à parvenir à la table de destination, avec une configuration économique à chaque étape. Nous imaginons sans mal un processus pour des flux de données bien plus volumineux en exploitant la forte scalabilité des solutions. Les outils de visualisations subséquents peuvent dès lors fournir des informations extrêmement proches du temps réel et ainsi permettre de tirer le meilleur parti de la constellation IoT déployée. Un autre grand avantage de cette solution est le stockage de la donnée historique pour permettre d’avantage d’analyses supplémentaires. Sans oublier la facilité de mise en place et le prix très intéressant.
Retrouvez la démonstration de ce use case lors de notre Live LinkedIn du 30 septembre prochain, cliquez sur le lien ci-dessous pour vous inscrire.
Live IoT Data Streaming





